Big hair, pop music and high-energy dance moves might be what most people remember about the 80s, but those fads pale in comparison to the real advances that were made in technology. Tech breakthroughs like CDs, Walkman’s, boomboxes, PCs and even the first mobile phone changed the way we do business and cleared a wide path for the next century. IBM, the iconic granddaddy of them all, had to make way for newcomers Oracle, Microsoft and Apple.

And, I was there, in the midst of a technology boom—to learn from it all.
I’ve worked in software development for many years starting back in the late 1980s with Oracle Database version 5.0 and Oracle Forms version 3.0. I’ve watched code evolve, become more complex and experienced the benefits of code review and automation.
In the late 1980s was when my experience of working with Oracle PL/SQL procedural code first started and, back then, I had little understanding of the need for coding standards apart from basic object templates and the need to document everything as you go along. So long as the code compiled and ran, that was considered good enough – right?
These days, the PL/SQL language has evolved significantly with more sophisticated constructs and advanced data types enabling developers to build more advanced programs. With that complexity, however, comes the increased likelihood of failure.
Other significant changes include the adoption of DevOps and automated continuous integration and continuous deployment (CI/CD) pipelines. The purpose of automated software delivery pipelines is so that business can react faster to market changes and competitive threats and ultimately grow revenue and be more successful.
This aspiration relies on the ability to automate the process of minimizing code defects and technical debt. Without clearly established code review best practices that include objectively agreed upon code quality checklist and rules, this goal is difficult to achieve.
One other change we see is the potential exposure by companies on the personal and sensitive information stored in their databases and accessible by developers and other non-production functions. We see the competing interests of developers/testers who need production data for more effective testing and the operations teams who have to protect that data in order that their company is compliant with data privacy regulations like GDPR, CCPA, HIPAA and other.
Cost of poor software quality
The costs associated with poor software quality are huge. A 2021 report by the Consortium for Information & Software QualityTM (CISQTM) reports on the cost of poor quality in the US and found that the total estimated cost was $2.08 trillion. The cost of technical debt (the implied cost of additional rework to correct defects and errors) alone was estimated to be $1.31 trillion.
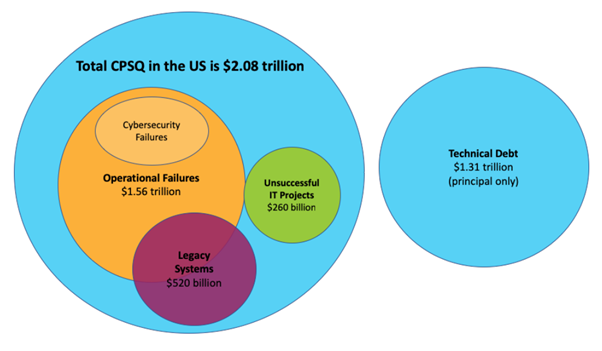
Figure 1 – Cost of poor software quality in the US in 2020
When we look at today’s trends of increasing digital transformation, software quality becomes even more important to success. Many digital transformation projects fail because of the lack of attention to software quality, rather than any lack of focus on technology or the business.
Some years ago, I worked with a Toad customer in China in the financial services sector who really took code quality seriously. They used Toad’s Code Analysis features as fully automated code QA tool and if excessive defects were found in their PL/SQL code, the developers responsible would be penalized by way of a cut to their bonus. That’s an extreme example, but the point is, the reason this company clearly took code defects seriously was because there can be a financial impact to business if defects ultimately lead to business interruption or loss of service.
“Best Practices” alone don’t work
Many companies I visit, when asked, claim they have a coding “best practices” manual which their developers are supposed to use. I’ve seen many of them and some are really good taking up 2 or 3 lever-arch files. However, when asked “how many of your developers actually use the recommendations, the embarrassing answer is usually “very few”.

What that basically means is that static code reviews, which are supposed to assess the quality of the code and it’s fitness-for-purpose in production, is piecemeal at best and are essentially nothing more than “guidelines” – which very few people follow – that’s just human nature.
What is the purpose of a code review? If we actually set out what the goals should be in order to take a standardized approach to ensuring optimal code quality, we’d probably consider some or all of the following:
- Reliability
- Do we have the ideal set of best practice rules identified?
- Is everyone following all the prescribed rules all the time?
- Consistency
- Is everyone interpreting all the rules the exact same way?
- Will different people apply the same rules to different ends?
- Measurability
- How do we measure and attribute success of this methodology?
- Can we quantify the cost versus savings of this methodology?
- Effectiveness
- Will we simply and easily get results of better engineered code?
How many of you can honestly say yes to more than 3 of these?
Classic “peer” reviews, for which I’m sure many of you reading this will have been involved at some stage in your career, involve having someone else read your code to see if there are any obvious issues.

There are some key flaws to this approach.
- They are subjective and time consuming.
- They are generally incomplete, focusing on basic structure and readability.
- In the interests of time, they don’t cover all the code in the application.
- No documentation, analysis or reporting. What does “good enough” look like?
So, peer reviews aren’t exactly taking a scientific approach to the problem and when I ask companies how seriously they take static code analysis, the answer is it’s not a key priority for them compared with (say) testing and performance.
However, with the emergence of integrating database change management into DevOps driving the need to automate many development processes, static code quality analysis is being demanded by organizations that need to accelerate their build and release processes.
What’s needed is a code review tool.
What should I look for in a code review tool?
Look for these features when evaluating a SQL code review tool:
- Enables objective code review
- Enables consistent code review
- Enables automated code review
- Flexible
- Rules-based
- Contains a visual indicator
- Group, prioritize and categorize different rules based on severity level
- Coding hints and suggestions (which also teaches)
A good code review tool enables developers to perform code reviews in a way that’s objective and consistent and can ultimately become automated.
The tool needs to be flexible so that you can adapt the way it works to ensure the enforcement of the coding standards that are applicable to a project or across the company. This implies that the tool should be rules-based, where each rule relates to a specific aspect of code quality (such as how you declare variables, or which exception handler you use) and that, depending on the number and types of rules you choose, the code can be parsed and checked to see whether the program complies with the established rules or not.
A visual indicator to inform the developer of the extent to which their code complied with the coding standards. This will enable the developer to target any detected issues and make the necessary corrections.
Of course, different coding standards can have different priorities; some of them critical, most less critical, so there needs to be a way to group different rules depending on their criticality (or severity level) and maybe also on categorization, such as program structure, performance, readability or maintainability.
And it would helpful if this tool worked like a “coding coach” and offered hints that told the developer which an issue was flagged in the first place.
This is important so that developers don’t feel like they are being punished for the quality of their code but offered advice so they can become better developers in the future.
As I mentioned before, the other benefit of a rules-based code review tool is that code reviews can be consistent and can become automated.
Being able to programmatically call this functionality as part of an automated build process means that you have a really effective way to speed up software delivery without compromising code quality.
So, why does code quality matter?
Implementing a rules-based approach to your PL/SQL code reviews is particularly important if you are considering integrating Oracle database development tasks into DevOps and automated CI/CD pipelines with ambitions of 2 – 3 week sprints. Peer reviews are simply not practical, because they are not objective, consistent and cannot be automated.
With all the disruption and costs associated with unplanned development cycles that come from rejected or poorly performing code, repeatable, objective code reviews are a must for you individually as well as your organization.
Code reviews help to minimize technical debt, that builds up under ongoing pressure to release code changes faster. This debt will only increase as time goes by.
I hope you enjoyed this blog. Make sure and read part 2 and learn about Quest® Toad® for Oracle Pro, which has a built in code review tool and answers the question, How does code review work?
Related links:
Blog: Code analysis: Why PL/SQL Code Quality Matters
Webcast: How a Code Review Tool Can Help You Write Team-friendly PL/SQL [Webcast]
Video: Advanced code review using Code Analysis
Video: ‘Dan’s Dozen’ Quick Toad Tips – Tip #9 – Code Review
Blog: Toad Code Analysis
Blog: Analyzing Code with the Toad for Oracle Code Analysis Tool
Blog: 8 ways to increase your database power and flexibility
Blog: 5 fitness tips for PL/SQL code
Blog: SQL tools – 8 ways you can’t live (or work) without them
Have questions or comments?
Head over to the Toad for Oracle forum on Toad World®! Chat with Toad developers and lots of experienced users.
Help your colleagues
If you think your colleagues would benefit from this blog, share it now on social media with the buttons located at the top of this blog post. Thanks!
Start the discussion at forums.toadworld.com