So, you've created an Oracle Cloud Database (which is pluggable). You can connect to it and copy files to it using Secure FTP.
Now you want to move data into it from one of the databases at <your company>. I’ll show you how to do that using Toad.
What can you move with datapump?
Datapump is great. You can move individual tables (one or multiple, all or some of the data in each). All datatypes are supported. You can move an entire schema or multiple schemas. You can move a tablespace. You can move the entire database. It's very fast and very flexible. Most likely, the slowest part of this process is going to be copying files across the network. OK, that's my Datapump speel.
In my example below, I'm going to move 3 tables, but it could easily be any other type of object that data pump supports.
Exporting
The first step, naturally, is to export data from the source database. From Toad's main menu, click Database -> Export -> Data Pump Export.
Here it is. I've loaded my three tables into the grid using the "Add" button at the bottom of the window.
We don't need to do anything on the "Queries", "Views as Tables", or "Filters" tab for this kind of export. So, click on the "Params" tab.
I want to create the table and load data into the target, so I set "Content to export" to "All", and I want my export file to be as small as possible so I've enabled compression. If you are going to repeat this process, you'll wan to check "overwrite existing dump files". Click on the "Files" tab next.
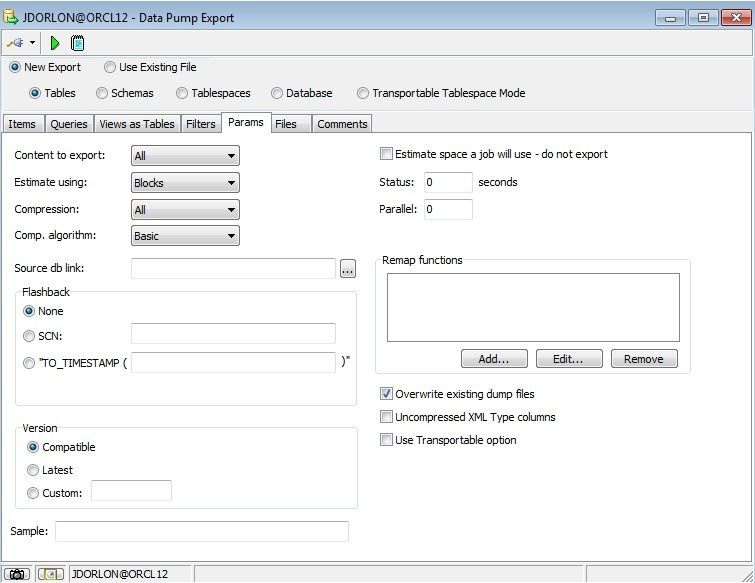
On the "Files" tab, the only things you need to set is the "Parameter file name", "Directory", and "Dump file name". The Parameter file is a file that Toad will create on your PC which contains the settings for the Data Pump export. The dump file is created on the server, in the directory that you choose with the "Directory" dropdown. And the "Dump file name" is the file that Oracle creates which contains your data. Add some comments on the comments tab if you want, then click the green triangle icon to start it.
This window will appear, and you can watch the progress of the export as it happens.
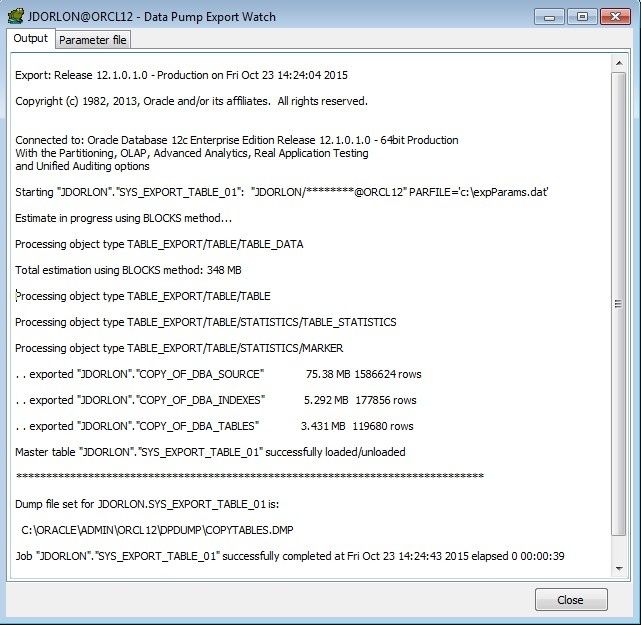
I really don't have that many rows in DBA_SOURCE, DBA_INDEXES, and DBA_TABLES. I inserted extra rows so certain things might be a little more meaningful. See where it estimated the file size to 348MB? Since I turned on compression, the file size was only about 90Mb. Also, notice that I'm exporting around 2 million rows and it only took 39 seconds.
Errors?
The same day I first published this blog, I got an email from someone who said he'd been working with Data Pump and he's been seeing some errors (Wow! Someone read this!).
If this happens to you, it's because your Oracle client is older than the server that you are connecting to.
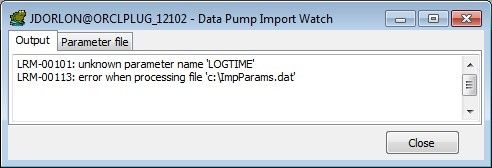
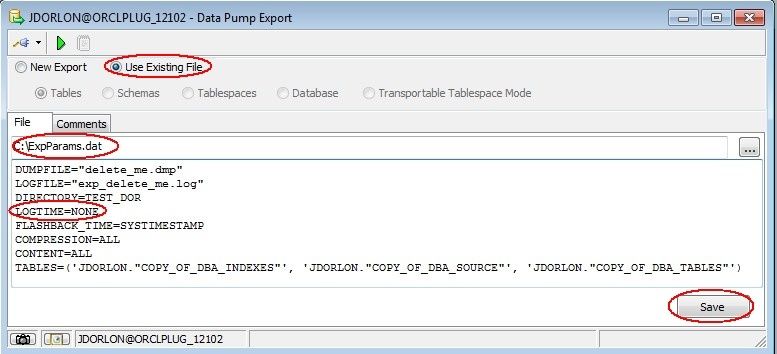
Ideally, with Data Pump, you should use the same client version as your server version (and be sure to pick the correct datapump executables in Toad under Options -> Executables), but as a workaround, you can click your Data Pump Wizard over to "Use Existing File", then specify the same parameter file that you specified a few minutes ago. When it loads in the GUI, remove the incompatible parameters, and click "Save", then run it from there by clicking the green triangle icon.
Copying the file to the cloud server
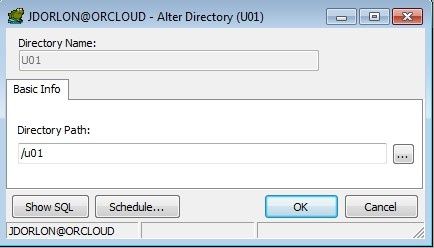
The file can go pretty much any where you want to put it on the cloud server, but a DIRECTORY object will have to point to whatever operating system folder that you put the file in. To keep the typing to a minimum, I made a directory on the target database called U01 that points to the /u01 folder.
Here's a refresher on how to copy files to using Secure FTP.
Importing
You're done with the source database, so disconnect from it. Connect to the target database and from Toad's main menu: Database -> Import -> Data Pump Import
Like before, there are just a few parameters that we actually need to set. We don't have to choose tables or anything since we're importing everything in the file (so choose "Entire dumpfile"). Also, I'm choosing "If table exists – replace" so I can run this over and over without errors. Click the "Files" tab.
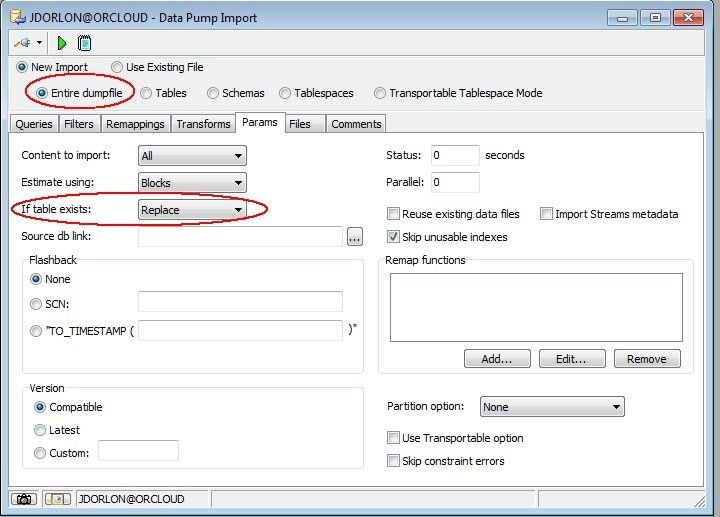
Like before, "Parameter file" is created by Toad and it contains all of your Datapump settings. We put the file in the U01 directory, and the file was called COPYTABLES.DMP. Remember, file names are case sensitive in Unix. Click the green triangle to start it.
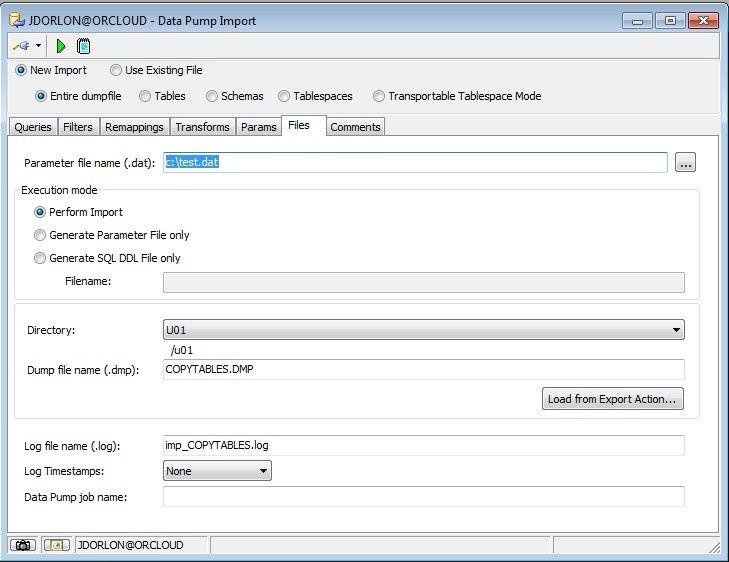
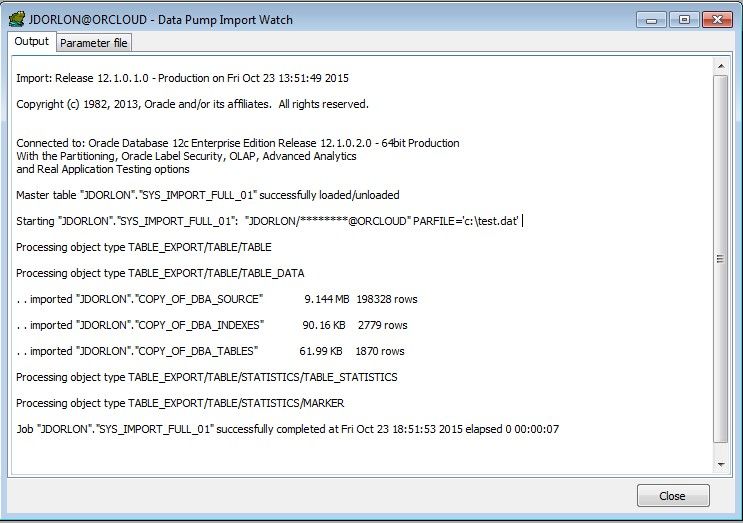
And there's the progress dialog again. Done in 7 seconds! It's fast!
Can I run the whole process in one click?
That's what everyone wants to know, right? The answer is kind of a qualified "yes". Toad's Automation Designer has actions for Data Pump Import/Export and FTP. So you could create one "app" that has an Export, a FTP, and finally an Import. The only catch is that the Import/Export actions are threaded, which means that if you try to run that app as a whole, what happens is that the Export kicks off and then immediately after, the FTP kicks off, without waiting for the Export to finish. You can work around it with the "Shell Execute" action though. Use a Shell Execute action to call data pump instead of using a data pump action. For the FTP action, I used a UNC path to get to the file on the source database server (since that is different than the PC that I'm running Toad on).
So here's what that would look like:
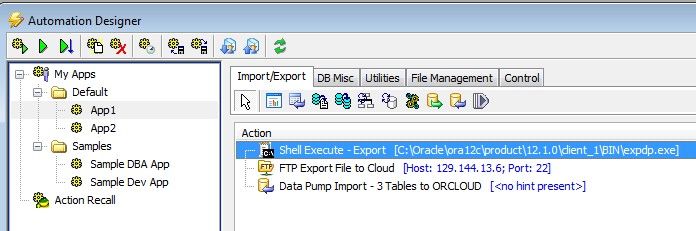
Then, with Toad connected to the source database, you could click the top-left toolbar button to start the export, file transfer, import. Since nothing is after the Import, we don't need to substitute a Shell Execute action for that one.
Start the discussion at forums.toadworld.com