In the previous parts of this article series, we started to look at Amazon AWS and its Relational Database Service (Amazon RDS). This included Amazon’s own Aurora database with MySQL compatibility and Aurora with PostgreSQL compatibility. We examined the similarities between PostgreSQL and Oracle.
We then noted a few of the benefits of using Aurora with PostgreSQL compatibility as compared to using PostgreSQL on-premises, or PostgreSQL on Amazon RDS itself. Next, we looked at the benchmark results for PgBench and SysBench for the two test systems, which demonstrated the improvement in performance for Aurora.
We then started to look at the performance architecture of Aurora. Initially, we saw how, in an RDS multi-zone setup for PostgreSQL, every user operation was resulting in multiple writes with sequential and synchronous steps, increasing latency and jitter.
In this sixth part of the article series, we will have a look at the write IO Traffic in an Amazon Aurora Database Node and see for ourselves the improvements in the write flow. This traffic is illustrated in the diagram below.
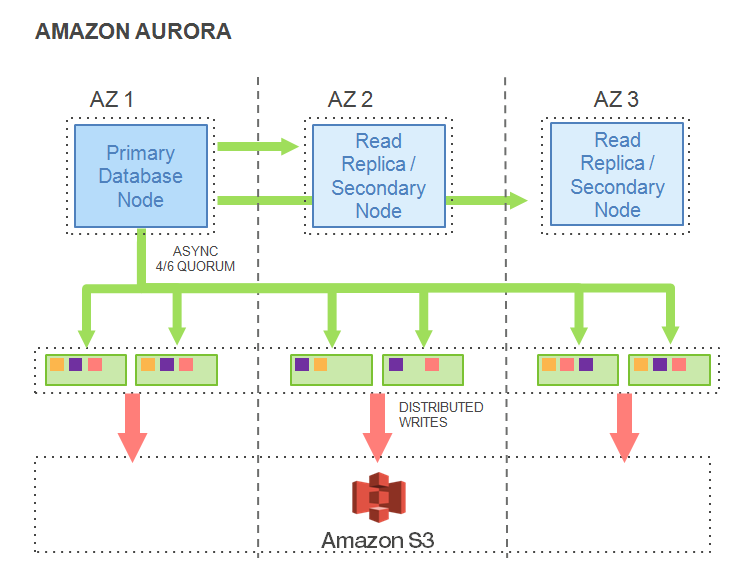
As before, the larger orange arrows signify Data writes, the yellow blocks signify WAL (Write Ahead Log) data, and the purple blocks signify Commit Log and file data.
First of all, to improve the IO flow, a ‘boxcar’ technique is used for log records. This is a method of optimizing IO by shipping a set of log records in what can be termed a ‘boxcar’. The boxcar log records are fully ordered by their log sequence number (LSN).
The records are shuffled to appropriate segments in a partially ordered state, and then ‘boxcar’ed to storage nodes, where writes are issued. An asynchronous 4 out of 6 quorum is used to reduce IO and network jitter. Writes are sorted in the buckets per storage node for getting more efficiency out of the network.
Since the storage system is transaction aware, it acknowledges groups of actual transactions instead of acknowledging writes coming back. The difference is important, since this minimizes chatter between the storage nodes and the primary database node.
What are the benefits of this approach? Only WAL records will be written, and all the steps are asynchronous. There are no data block writes (such as a checkpoint or cache replacement). The net result is that even though there are six times more logical writes than a normal “traditional” monolithic database, there is actually nine times less network traffic in the case of the Aurora database. This is mainly due to packing commits together and only writing log records.
The system in general is also more tolerant of network and storage outlier latency as a result. As far as the performance goes, this results in two times or better PostgreSQL Community Edition performance on write-only or mixed read-write workloads.
Let us look at what goes on at the storage nodes. The storage node architecture is seen in the diagram below.
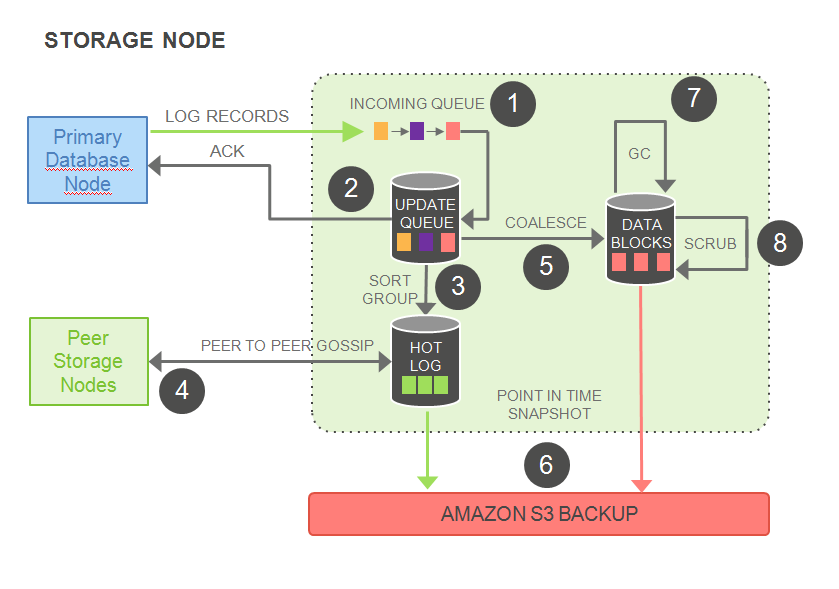
In this storage node architecture, the IO flow can be described as follows:
As the first step, the batch of log records is received and added to the in-memory queue. In the second step, the records are persisted to the log in the local SSD and an acknowledgement is sent. In Step 3, the records are organized and the gaps in the log are identified. Next, in Step 4, any storage node with log gaps interacts with the peer storage nodes to fill in the gaps.
In the fifth step, log records are coalesced into new data block versions. In Step 6, the storage node periodically stages log and new block versions to Amazon S3 as a backup.
Step 7 involves a periodical garbage collection of old versions, and in Step 8, the storage system periodically validates CRC codes on the blocks (i.e., background verification checks are performed on the storage).
We can observe from this that only Steps 1 and 2; i.e., receiving the batch of log records, persisting the records to the logs in the local SSD, and acknowledging this back, are in the foreground latency path. These Steps 1 and 2 are the only ones that block database operations. All the steps are completely asynchronous to the database.
It can also be seen that the input queue in this case is far smaller than PostgreSQL. This kind of architecture favors latency-sensitive operations (since most of the steps are synchronous, as shown in the storage architecture above) and uses disk space to buffer against spikes in activity.
Next, let us talk about read replicas as supported by Amazon Aurora. How would the IO traffic work in such replicas?
To find the answer, have a look at the following diagram, which compares PostgreSQL Read replicas to Aurora Read replicas.

In the PostgreSQL case, the master database ships the redo (WAL or the Write Ahead Log) to the replica database, which is then written to disk, and then applied in a single-threaded process. When the replica applies the redo, it needs to read the log if not already in memory. Then the changed blocks need to be written to the replica data volume.
This means a lot of IO for a simple read replica. As we can see in the diagram, the write workload of 70% will be similar in both the plain PostgreSQL instances. Note also that independent storage is used for the master database and the replica database.
In the case of Aurora, the replica shares the storage with the master database. The master database ships the redo (WAL or the Write Ahead Log) to the replica database. The redo records are applied directly to the cached pages and do not need to be written out. Currently, Aurora will read pages from storage to apply the redo only if it is not cached.
The net result is that since there are no writes being done on the replica, there are more resources to support read queries. This means the replicas can do more read work (100% new reads, as shown in the diagram above).
In the next part of the article series, we will look at the database cache and how it stays “warm” in the case of Aurora. Finally, we will examine the new “Performance Insights” recently announced by AWS.
(Disclaimer: The views expressed in this article are the author’s own views and do not reflect the views of Amazon Web Services (AWS) or Oracle Corporation. The author has written this article as an independent, unbiased cloud architect/consultant. The benchmark results and graphs in this article are from AWS public presentations.)
Start the discussion at forums.toadworld.com