In the previous parts of this article series, we had a first look at Amazon AWS and the Relational Database Service (Amazon RDS) that it offers to customers around the world. We zoomed in on Amazon’s own Aurora database with MySQL compatibility, followed by the PostgreSQL compatible version. We looked at the similarities between PostgreSQL and Oracle, and also the missing bits that were possible only on the Oracle Database Cloud, such as true active-active read and write horizontal scaling with the Real Application Cluster (RAC) option. Next, we looked at some of the benefits of using Aurora with PostgreSQL compatibility.
In this fifth part of the article series, we continue talking about the benefits, and then look at the benchmark tests completed by Amazon that show the performance benefits of Aurora PostgreSQL over a PostgreSQL database deployed on RDS. First, more on the benefits.
Amazon Aurora offers the feature of instant Crash Recovery. In the case of the traditional databases most of us are used to, when a crash recovery takes place, redo or archive logs since the last checkpoint need to be replayed so that the database is brought up to date. However database checkpoints are not that frequent; they are normally at least a few minutes apart due to performance considerations. If the transaction volume for the database is huge, then crash recovery would mean applying a number of logs and that takes time. Especially because this application of logs is single-threaded in MySQL and PostgreSQL, and it also requires a large number of disk reads and writes.
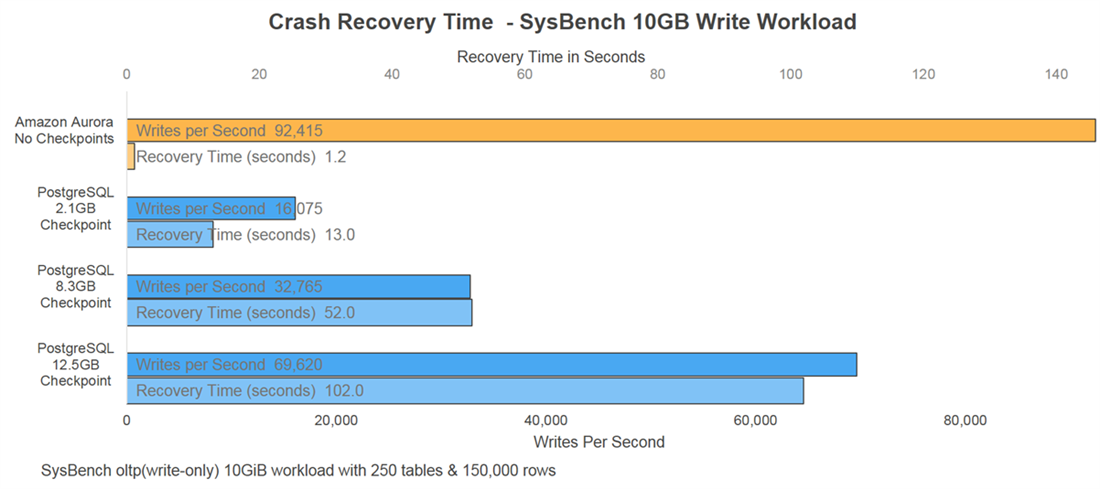
In the case of Amazon Aurora, no replay of logs is required at startup, simply because the storage system is transaction aware. The underlying storage replays log records continuously, whether in recovery or not. The coalescing that takes place is parallel, distributed, and asynchronous. A recovery time of 1.2 seconds is seen for a SysBench OLTP (write-only) 10GiB workload with 250 tables and 150,000 rows, as per AWS internal tests.
With Amazon Aurora, there is also a faster, more predictable failover from the primary database to the secondary database. In the case of Amazon RDS for PostgreSQL, failover times of approximately 60 seconds are seen, whereas in the case of Amazon Aurora, failover times of less than 30 seconds can be achieved.
Now we will look at some of the performance benchmarks. Amazon internally tested the performance of Amazon Aurora with PostgreSQL compatibility against PostgreSQL 9.6.1 on RDS. The benchmarking configuration is seen in the diagram below:
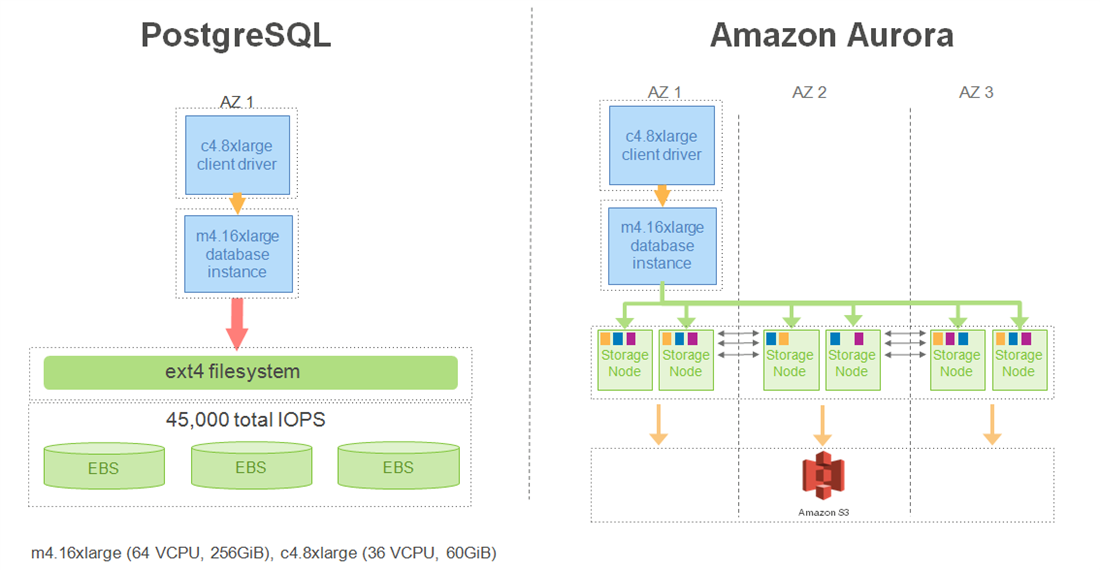
AWS m4.16xlarge instances were used for the database servers, and c4.8xlarge instances were used for the client servers in both cases. The RDS PostgreSQL database used provisioned IOPS storage with a total of 45,000 IOPs. This was made of three 15,000 IOPs Amazon Elastic Block Store (Amazon EBS) volumes that were effectively striped into one logical volume with an ext3 file system.
WAL (Write Ahead Log) compression was enabled, which is a new feature from PostgreSQL 9.5 onwards – this compression reduces the I/O that is caused by the Write Ahead Log being written to the disks, but at the cost of CPU cycles. Aggressive autovacuum was also used in an effort to increase the performance of PostgreSQL, along with WAL compression.
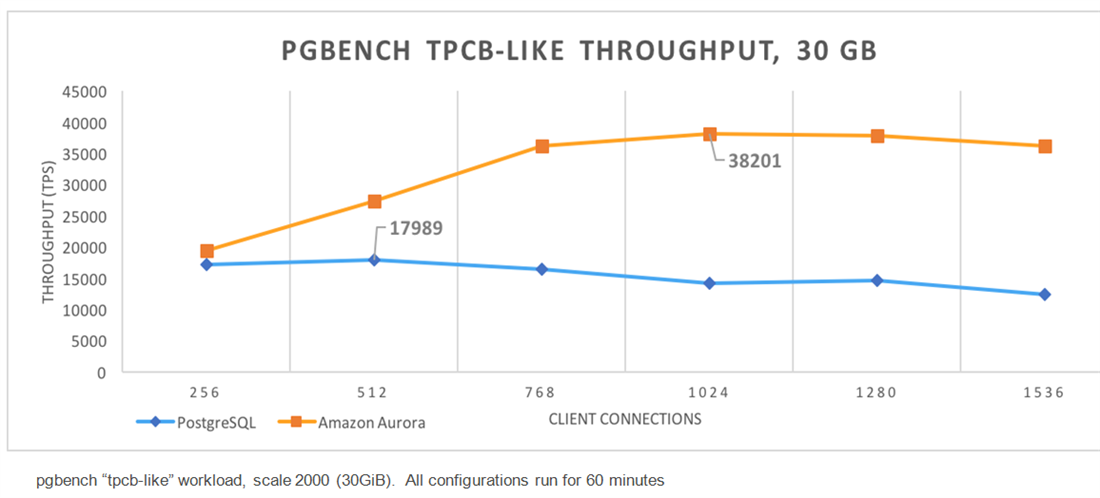
Next, PgBench, the well-known benchmarking tool for PostgreSQL, was used with a scaling factor of 2000, creating a 30GiB database. Different numbers of client connections were used for 60 minutes each, and the database was recreated immediately prior to each run. The results were as follows and are obvious – Amazon Aurora is more than 2 times faster than just RDS-based PostgreSQL using the PgBench tool.
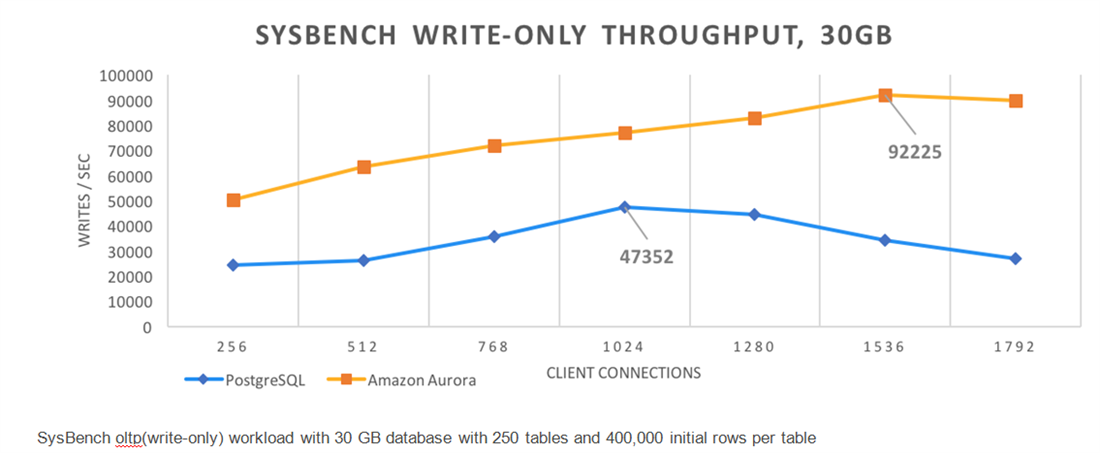
When the SysBench tool was used, with write-only throughput, on a 30GiB database with 250 tables and 400 thousand rows per table, the performance of Aurora was three times better than RDS PostgreSQL when the number of client connections had reached the 1792 mark, as can be seen in the graph below.
On the other hand, a SysBench write-only workload of 10GiB with 250 tables and 25,000 initial rows per table, with 3,076 clients and after a ten minute warmup period, reached a sustained SysBench throughput of over 120,000 writes per second.
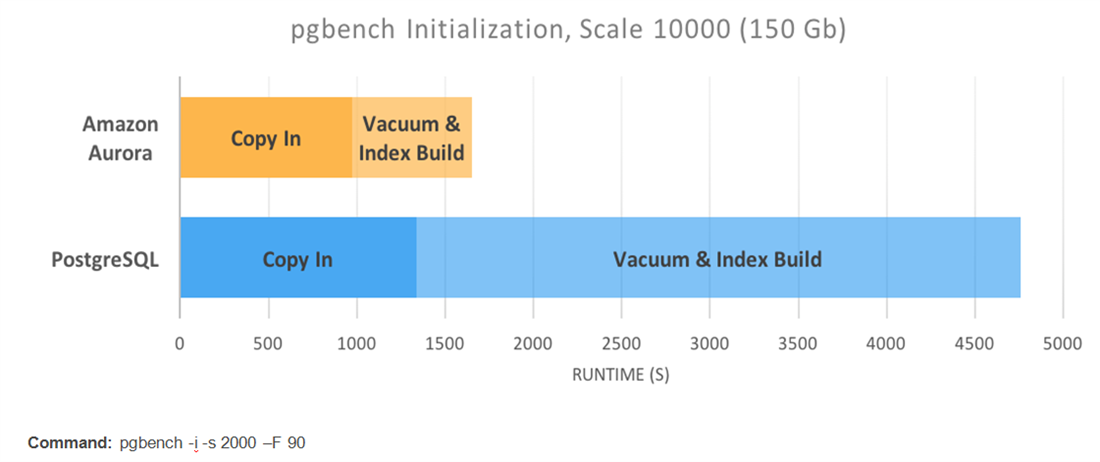
Regarding database initialization time, which is important for large databases, the standard PgBench benchmark was used for a 150GiB database (using the scale of 10000). It was found that database initialization was considerably faster in the case of Aurora, as can be seen in the graph below – approximately three times faster. The Vacuum and Index build stage seems considerably reduced in comparison to RDS-based PostgreSQL.
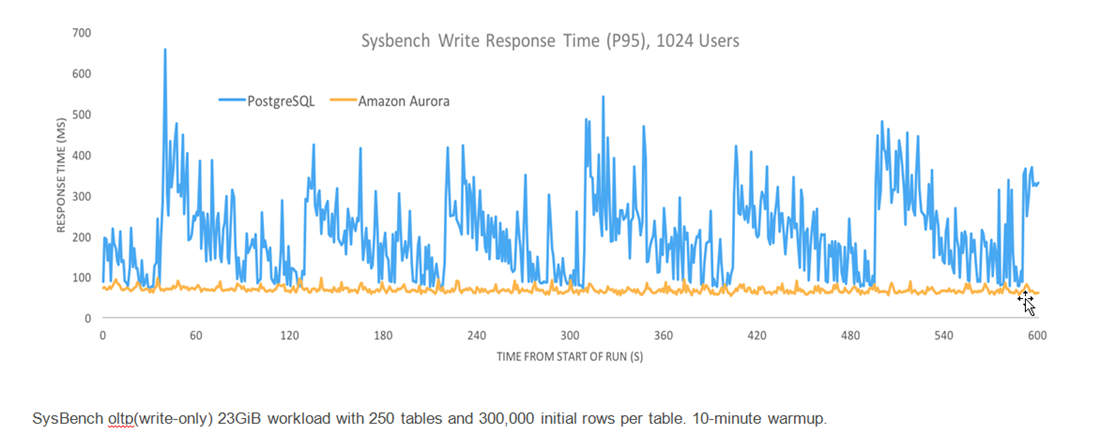
The response time for Aurora under a heavy write load was more than two times faster than RDS PostgreSQL and also 10x more consistent. This was for a SysBench OLTP (write-only) 23 GiB workload after a 10-minute warm up with 250 tables and 300,000 initial rows per table, as seen in the graph below.
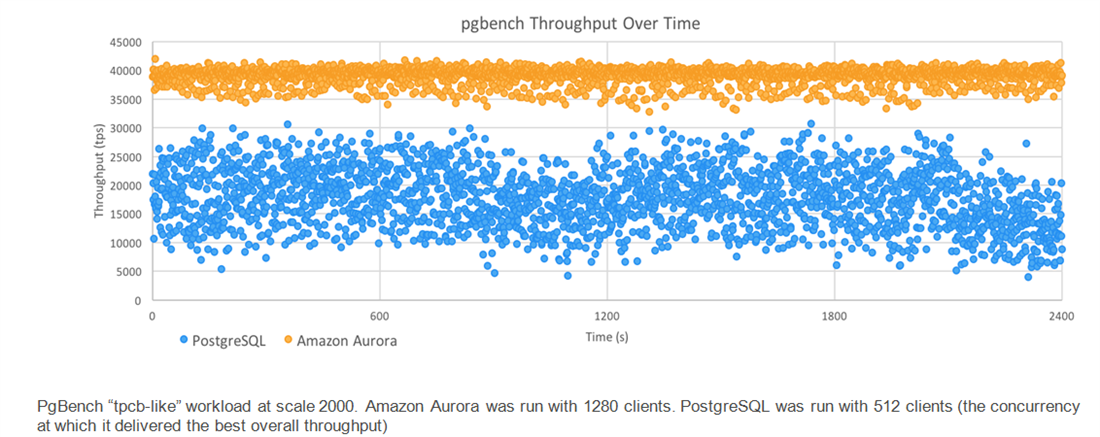
Another PgBench test showed that consistent throughput is observed more so in the case of Aurora. When running at load, performance was seen to be more than three times more consistent than RDS PostgreSQL. The standard deviations were seen to be 1395 TPS and 5081 TPS, so it was also about 1/3 of the jitter.
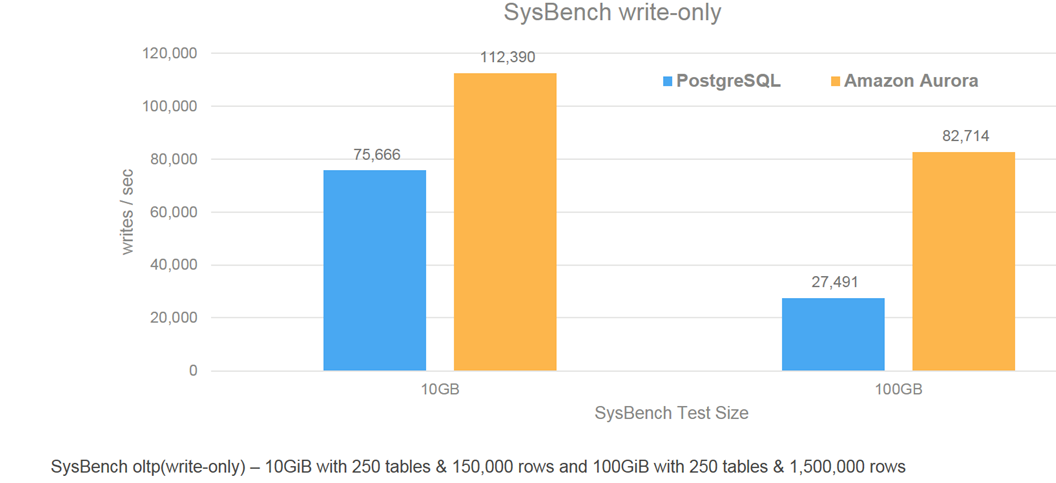
Also, as the test database grew from 10 GiB to 100 GiB, the write only SysBench OLTP benchmark shows the Aurora database scales three times faster.
And finally, crash recovery for Aurora is much faster due to the transaction-aware storage system. The result is a crash recovery that is 85 times faster than RDS-based PostgreSQL.
Let us now take a closer look at how Aurora is able to achieve such performance improvements, and for that we will need to examine the cloud-based architecture of Aurora.
First, for better performance Aurora needs to be able to do less work, and this is done by achieving fewer I/Os and minimizing network packets. Secondly, more efficiency can be achieved by processing asynchronously, batching operations together, and using lock-free data structures.
Examine the following RDS-based multi-zone setup for PostgreSQL. How does the I/O flow happen? The primary database would first issue a write to the Amazon EBS storage. The EBS then issues the write to its mirror, and an acknowledgement is sent when both writes are completed. The next step is to write to the standby instance, which is then issued as a write to the standby’s EBS storage, and its own mirror.
In the diagram below, the yellow arrows signify WAL writes, the orange arrows signify data writes, and the smaller purple arrows show commit log and file writes.
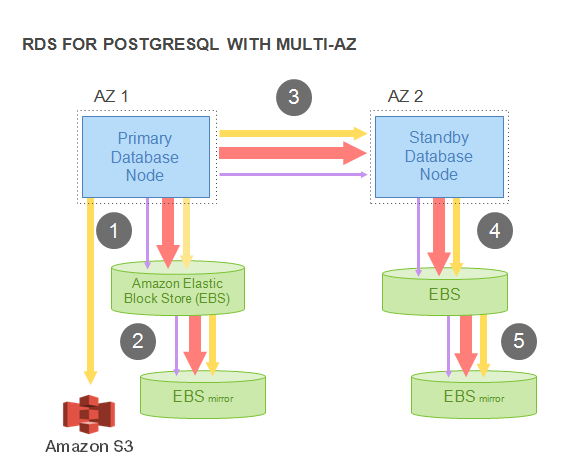
It is obvious here that every user operation is resulting in multiple writes. Steps 1, 3, 5 are clearly sequential and synchronous. Due to this, latency is increased, and jitter is also amplified. This obviously has an impact on the database performance.
In the next part of this article series, we will have a look at the write I/O traffic in an Amazon Aurora Database Node, and see for ourselves the improvements in the write flow.
(Disclaimer: The views expressed in this article are the author’s own views and do not reflect the views of Amazon Web Services (AWS) or Oracle Corporation. The author has written this article as an independent, unbiased cloud architect/consultant. The benchmark results and graphs in this article are from recent AWS public presentations on the benefits of the Aurora with PostgreSQL compatibility database.)
Start the discussion at forums.toadworld.com