In the previous parts of this article series, we had a first look at Amazon AWS and the Relational Database Service (Amazon RDS) that it offers to customers around the world. Besides multiple third-party databases in RDS (such as MySQL, Oracle, MS SQL server, PostgreSQL and MariaDB), Amazon’s own Aurora database was released first with MySQL compatibility, followed by a PostgreSQL compatible version very recently in late 2016.
But why was Aurora with PostgreSQL compatibility released? As per Amazon, this was due to customer demand and interest in PostgreSQL along with AWS optimizations for the cloud. Perhaps as an option for greenfield deployments, or even migration from other databases. Amazon now offers Aurora as PostgreSQL 9.6 on Amazon Aurora cloud-optimized storage, with resulting performance two times better than PostgreSQL alone, as per internal tests by AWS.
In fact, PostgreSQL by itself is a database that is considered to be “compatible” with the Oracle database, and this is primarily because of its own PL/SQL-compatible language called PL/pgSQL. AWS provides a Database Migration Service (DMS) and a Schema Conversion Tool that could often fall short of converting Oracle stored procedures and functions – the application code in the database layer – to a target non-Oracle database, so the compatibility of PostgreSQL’s PL/pgSQL with Oracle’s PL/SQL could possibly lead to further enhancements in the AWS Schema Conversion tool, such that it could convert most of the application code at the database layer.
In the previous parts of this series, we looked at other similarities between PostgreSQL and Oracle. However, there are no stored “packages” (collections of procedures and functions stored together, and used frequently in Oracle) in PostgreSQL; neither is there any database clustering technology, as in the robust and mature active-active Oracle Real Application cluster (RAC) technology – the latter being a powerful means of scaling out reads and writes in a multi-instance Oracle database.
We looked at the replication facility in non-AWS PostgreSQL, and saw that there were no out-of-the-box facilities for managing standby databases such as what is available in Oracle Data Guard. The third-party tool suggested in the case of PostgeSQL replication was repmgr, which is obviously not used by all the PostgreSQL installations in the world today. This meant a reliance on scripts and manual commands issued at the command-line, which could lead to typing errors and deleting the wrong directory in the heat of the moment. The higher-level the replication tool, and the more automation there was, the better. This drawback in non-AWS PostgreSQL is compensated, however, by the way replication and failover are implanted in Aurora PostgreSQL, as we shall see.
Now for a look at the other benefits offered by AWS Aurora with PostgreSQL compatibility. As per Amazon, the failover time from the primary database node to a secondary node would be less than 30 seconds, and there is certainly high durability for the database; since in any AWS region that is selected for the database, six copies of the database are replicated automatically by the storage engine across three availability zones, as can be seen in the diagram below.
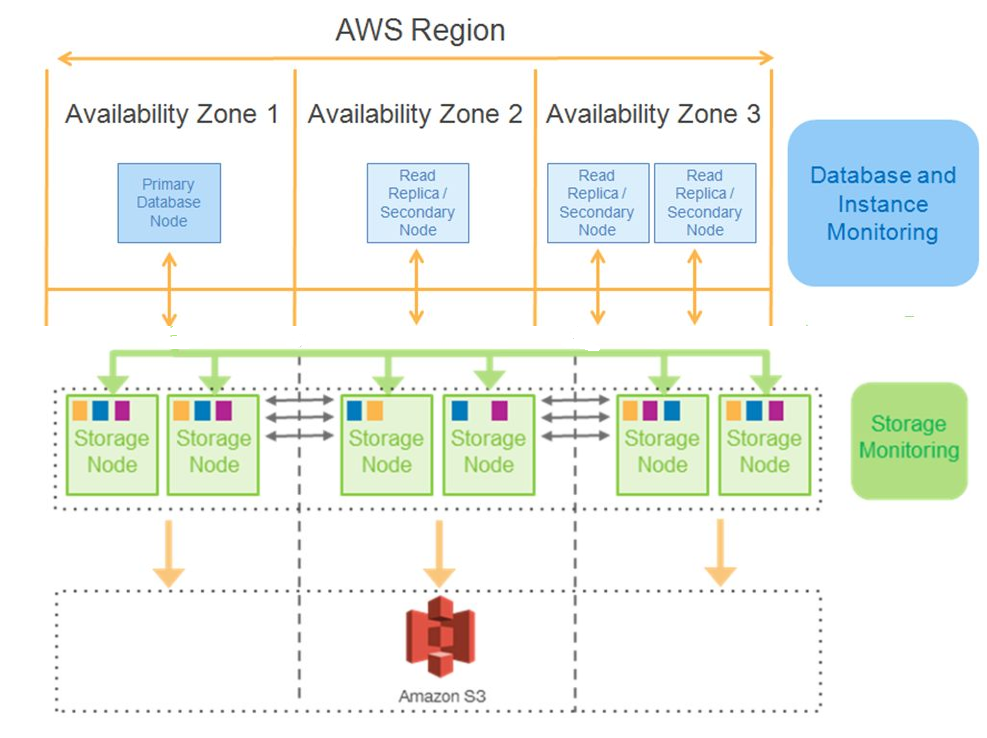
The storage layer was made transaction aware by Amazon Aurora, meaning that the database replication across the storage nodes uses a technology similar to redo records. The effect is that there is a lot less data replicated across the storage nodes. By the way, the storage volume used for the Aurora database can automatically grow up to 64TB.
Up to 15 read replicas of the database can be created in total, and the lag times for these are about 10 milliseconds, which is a lot faster than the 100 milliseconds lag time for read replicas seen in PostgreSQL on large systems. Besides, Aurora allows cloud-native security and encryption, using the AWS Key Management Service (KMS) and AWS Identity and Access Management (IAM). The database is also easy to manage, thanks to the Aurora management features.
In addition to the replication that occurs at the storage layer, there is a continuous automatic backup of the database via snapshots to Amazon S3. This means the database administrator needs no backup windows to back up the database; neither is there a performance impact during backup. There is also a continuous monitoring service in the background that monitors the nodes and disks to see if they need any repair. 10GB-sized segments are used as a unit of repair, or for rebalancing hotspots. A latency-tolerant Quorum algorithm system is used for reads/writes, and even if there are Quorum membership changes, they do not stall writes.
Basically, what can fail? Segment failures (disks) or Node failures (machines) or Availability Zone failures (network or datacenter) can occur. To increase the fault tolerance of the Aurora system, if four out of six writes succeed, they form the write quorum and the write is considered valid. Likewise, three out of six reads form the read quorum, and the read is considered valid – even if three database copies are not available. The system actually repairs itself, since peer-to peer-replication between the storage nodes takes place for repairs and this uses the CPU and network bandwidth of those storage nodes, not that of the main node.
Availability is also enhanced for the Aurora database nodes. Failing database nodes are automatically detected by the monitoring layer in the background, and replaced if required. If database processes fail, they are automatically detected and recycled. The database replicas are automatically promoted to primary if needed; i.e., a failover can take place automatically, but the client administrator can specify the failover order. To improve performance, applications can use the read replicas to scale out read traffic, with read balancing across read replicas also possible.
One of the good features is that continuous database backups take place all the time. A periodic snapshot of each segment is taken in the background in parallel, and the logs are streamed to Amazon S3 storage. The backup happens continuously without any performance or availability impact to the database nodes. For a database restore to a new volume, the necessary segment snapshots and log streams need to be retrieved to the storage nodes, and then the log streams need to be applied to the segment snapshots in parallel and asynchronously. This would clearly result in a faster database restore time.
We will continue looking at some more of the features of Aurora PostgreSQL in the next part of this article series, as well as the performance benchmarks and the performance insights monitoring service recently released by AWS. The next part is here.
(Disclaimer: The views expressed in this article are the author’s own views and do not reflect the views of Amazon Web Services (AWS) or Oracle Corporation. The author has written this article as an independent, unbiased cloud architect/consultant.)
Start the discussion at forums.toadworld.com