What is data modeling, why should I care, and what capabilities should data modeling tools offer? These are all important and timely questions that I’ll explore in this blog, each on their own. Finally, I’ll conclude with why I say this topic is both important and timely.

What data modeling is: good database design that translates to acceptable performance
The Wikipedia definition states that data modeling is the software engineering process of creating a data model for an information system by applying certain formal techniques. Even though software engineering was chiefly popular in the mid 1990s and early 2000s, that doesn’t suggest that it’s no longer relevant.
I’d propose that today’s extremely popular software development methodologies of agile and DevOps are simply the consequence of current software engineering best practices learned over the years.
As with all knowledge, it should build upon the existing foundation so as to add value. Therefore, agile and DevOps should include some prior software engineering best practices that’ll fit within the new framework. Data modeling does because you can’t build a truly successful application where the underlying database was thrown together ad-hoc by application developers writing relatively small portions of function specific code at a particular moment in time.
Programmers are fantastic at handling data in motion (i.e. the code), but not as proficient with data at rest (i.e. the database). You really can’t code your way out of abysmal application performance due to bad database design.
Stated another way, good database design directly translates into acceptable performance (i.e. efficiency).

What is a data model? Think blueprint.
So what is a data model? The Wikipedia definition states that a data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. That’s a mouthful.
Let’s instead view a data model as the blueprint of the objects within a database (i.e. tables) which represents the business concepts of entities (i.e. things) and that meets the business requirements for those entities (i.e. efficient). And much like old the TV show the “Brady Bunch”, blueprints are created by architects. While Mr. Brady might dawn a hard hat and visit a construction site, first and long before, he created complete blueprints for the customer to approve as meeting their needs prior to construction initiation.
Back in the 1990s and early 2000s those software engineers might have likewise created the data model for the entire database before coding. Whereas today under agile and DevOps, we probably will subdivide the overall database into functional areas or sub-models to be developed incrementally within the overall application’s SCRUM sprints.
So database design benefits from the traditional “divide and conquer” technique matched to the application phase. The resulting databases will meet the business requirements now for both effectiveness and efficiency.
Constructing a data model
When one constructs a data model, they do so by choosing and adhering to a specific drawing style known as Entity Relationship Diagram (i.e. ERD) notations. These notations include: Barker’s notation, Chen notation, IDEF1X notation, Arrow notation, UML notation, and Information Engineering notation (commonly referred to as IE or Crow’s foot notation).
Below is a complete comparison from agiledata.org between four of the more common ERD notations (IE, Barker, IDEF1X, and UML).
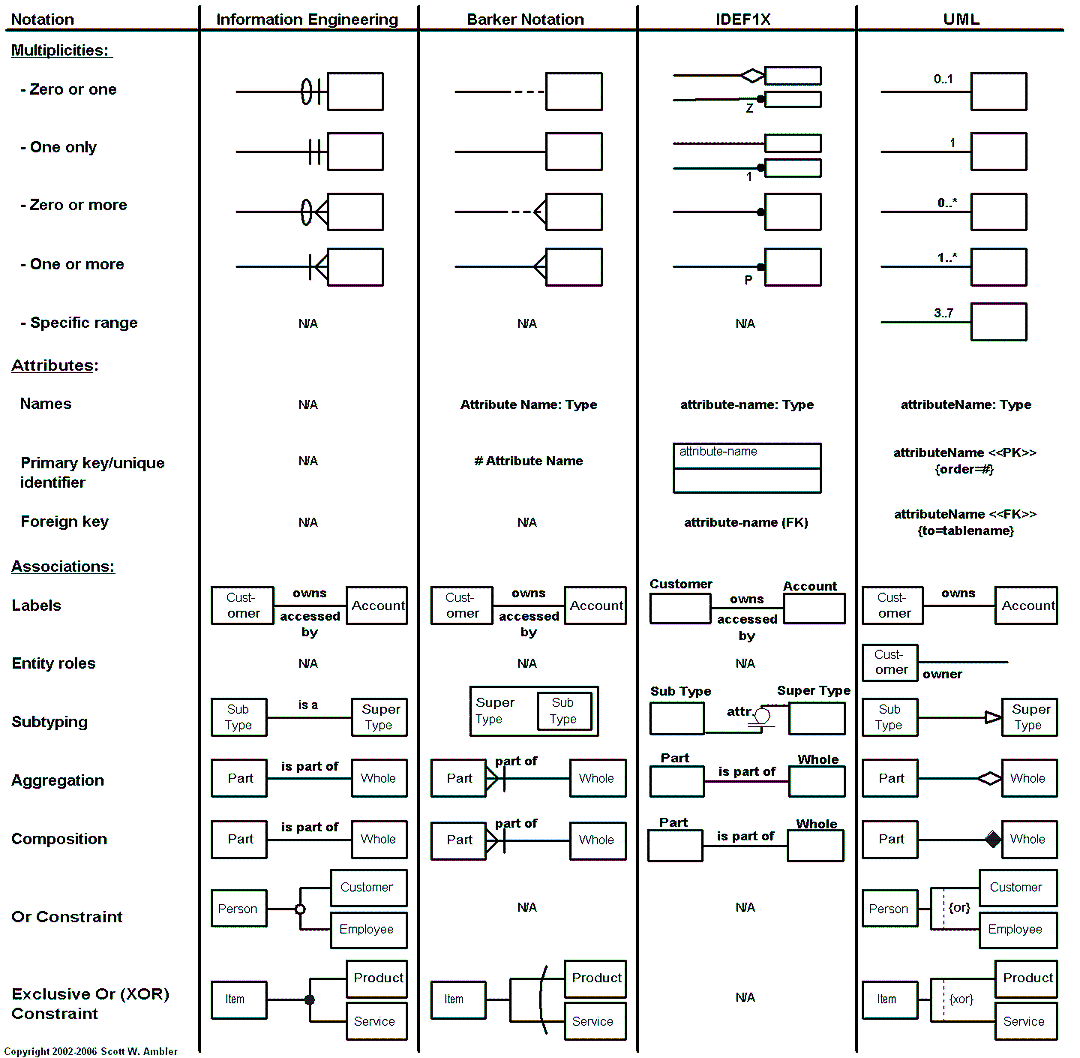
While these ERD notations may look significantly different, nonetheless they all permit one to model the same concepts. They will just look radically different. I’ll be using Information Engineering (i.e. IE) in my blogs and their examples. But you should choose one which meets your needs. For example, many DOD (i.e. Department of Defense) project might require the IDEF1X notation.
“We haven’t used data modeling yet and we don’t need it.”
So we’ve now basically defined what data modeling is, but why should you care? I’ve already made the case that for both effectiveness (i.e. meets all business requirements) and efficiency (i.e. the application performs well) that one needs to perform data modeling.
But I still encounter many cases where people simply are not convinced because they’ve done without to date with no major problems.
I’ve found over time that the following argument generally works. Would you permit the company building your single most valuable asset (i.e. your home) to do so with no blueprint, or would you allow them to just pound nails as they saw fit resulting in an ugly house– where you can see room by room the different phases of construction?
Data modeling isn’t just a good idea, it’s the essential building blocks
Data modeling is a good practice. What tools are out there and more importantly what capabilities should they offer? There are many data modeling tools out there, so I can’t really cover them all. However, there are few that have captured significant market share and are thus perceived as being best of breed. Moreover, there are a few different categories for these tools based on capabilities they offer.
I’m going to just list a few here, then I’ll go into how you should pick, based upon your needs, such that you select a tool that genuinely and completely meets your requirements. Note that I will be omitting those tools which are primarily intended for different purposes, but which also include a basic data modeling feature (e.g. Microsoft Visio, SmartDraw, Dia, Idera’s Aqua Data Studio, Quest® Toad® for Oracle, Squirrel, Dbeaver, DBVisualizer, and many others).
The Data Empowerment Summit
The Quest Data Empowerment Summit includes three unique tracks —Data Operations, Data Protection and Data Governance— with sessions about the latest trends, best practices and technologies to align these critical areas and close the gaps between your front and back offices. Don't miss out!
|


The best data modeling tools that are simple and budget friendly
If your needs are relatively simple and your budget constrained, then a lightweight data modeling tool may well meet your needs. I also would suggest that this category of ERD tools is best suited for project or departmental usage, but not for enterprise wide deployment. For example they generally don’t have centralized repositories in databases with concurrent model check-out/check-in and conflict resolution. Moreover, these tools often offer support for just one or a few of the ERD modeling notations. But let’s assume that you don’t need such advanced capabilities, then these tools may well be sufficient. Here’s a short list (in order) of tools that I feel are best of breed, light weight data modeling tools:
- Toad Data Modeler (formerly CASE Studio)
- Oracle SQL Developer Data Modeler
- DBWrench
- DBSchema
- XCase
The best data modeling tools that have robust capabilities, built for the enterprise
If your company is instead looking for an enterprise-wide data modeling tool where data models can be centrally maintained, where budget is more flexible, and where support is a key issue (including training and ability to hire resources familiar with the selected tool) then here’s my short list of the tools that I feel are best of breed, enterprise data modeling tools:
- Quest erwin® Data Modeler (probably largest familiarity and install base of any tool)
- Idera ER Studio
- SAP PowerDesigner (formerly Sybase)
Now for full disclosure, I once worked at erwin’s founding company: Logic Works (before acquired by Platinum, then CA, then a standalone company, finally acquired by Quest). I also formerly worked at ER Studio’s founding company: Embarcadero Technologies (acquired by Idera). At both of these companies I was a significant contributor to ER tool product design and planning.
I’ve also in the past worked as a freelance contractor for Sybase. But most importantly, I’ve used these three tools quite extensively. I’ve also written reviews for eWeek magazine (formerly PC Week) comparing database tools and specifically enterprise data modeling tools.
I’ve also seen other tools such as SPARX Enterprise Architect, IBM System Architect, and several others which have since been withdrawn from the market. While I have a deep history with my three top choices, I would argue they are well founded based upon experience. I can honestly say that an early adopter like erwin has a long and rich history which makes it easy to locate people who know the tool, and which offers all the key features any enterprise will likely need. In fact, for many people erwin is synonymous with data modeling.
6 features and capabilities you should look for in a large enterprise data modeling tool
With the best ER tools now identified, what feature or capabilities are important?
- First and foremost, it must support the notations you prefer.
- Second, it must work with all of the database platforms you’ll be working with.
- Third, it must offer both forward and reverse engineering with those databases. It must be able to generate database object creation scripts (i.e. DDL) from the data model, plus also be able to connect to the database and create a data model based upon what’s in the database.
- Fourth, it should offer a compare and sync capability that allows you to either update your model based upon what’s in your database or update your database based upon what’s in your model.
- Fifth, it has to support key physical database features you might use, such as views, triggers, partitioning, complex indexing, and advanced security.
- Finally, the DDL generated to create or alter database objects must be 100% accurate and support the concept of “extended alters”. It’s these two areas where many data modeling tools fail. I’ve seen data modeling tools that generate scripts that require few if any DBA review and alterations, to those where the DBA simply throws them out and codes the DDL manually to match the model.
I view data modeling tools much like a programming language compiler: it takes human readable definitions and turns them into machine executable (or database) instructions. If a compiler generates inaccurate or suspect code, then it’s not acceptable or usable.
That leaves “extended alters”, which many data modeling tools have major problems with. Let’s suppose that your data model has removed an attribute of an entity thus requiring dropping that column for the underlying table. A smart data modeling tool generating DDL for a modern, smart database might simply issue a one line DDL command such as the following:
ALTER TABLE table_name DROP column_name
This basically leverages the underlying databases capability to drop a column with a simple command where the database does any and all work behind the scenes to allow this to work. Years ago many databases did not offer this option, so some better data modeling tools could create the following type of DDL code which is often referred to as an “extended alter” to effect the desired results:
RENAME table_name TO temp_table_name
CREATE TABLE table_name (columns_minus_dropped_one)
INSERT INTO table_name SELECT columns_minus_dropped_one FROM temp_table_name
DROP TABLE temp_table_name
While these commands might have the desired end results, they have several problems.
- First, to copy a billion row table might take minutes to hours versus instantaneous in the prior example.
- Second, what about indexes, views, and security on the table – they would be lost by this example as very few data modeling tools can create a 100% complete extended alter as the complexity increases.
- Third, the table is essentially offline in this example as opposed to 100% online in the prior example.
Yes there are still some scenarios where an extended alter is required even today – but that’s now few and far between. However, many data modeling tools have not kept up and still do extended alters when not required.
So why is all this so important?
For most companies, data is the most valuable asset. Thus how you design the database to house this asset is more important than ever. Add to that the desire for data analytics and data scientists to be able to slice and dice the data to support major strategic business decisions, then having the data in a design that supports the application that places it into motion, as well as providing useful content while that data is at rest, is paramount. We must now design for both types of need.
Quest recently purchased erwin and that leaves many people wondering what will happen to Toad Data Modeler. In my opinion, this leaves Quest in an excellent position to satisfy the needs in two users. Toad Data Modeler is an affordable option for the individual developers who need a well-rounded data modeling tool. erwin DataModeler, on the other hand, is a full and robust solution that is aimed at larger enterprise businesses who need a comprehensive solution with broader DBMS support, rigorous design governance and enables maximum data model integration and reuse. That’s my experienced opinion, and as a fan of both offerings, I can’t wait to see how Quest positions them in the market in the months to come.
Related information:
Blog: Data modeling for the business analyst
Blog: Toad Data Modeler Reverse Engineering & Convert Model Wizards
IDC Datasheet: Quest Software Acquires erwin Inc.
Visit Quest erwin for more information about an enterprise data modeling solution.
Start the discussion at forums.toadworld.com