Hi,
I just wrote an article (click here to see article) that illustrates how B-Tree indexes work. Basically, they store key values that are to be looked up in their associated table. So, key values and rowids are stored at the index leaf level, and this information is useful to retrieve the rows that contain the key data. Oracle’s cost-based optimizer (covered in several related blogs) uses the fact that the index exists and other information such as clustering factor (click here for related article on index selection by Oracle’s CBO).
Index Tip 1
Know your data, know how your users will be accessing the data and make sure the data being requested would make for a good indexing possibility.
Oracle still uses the 20% rule in that if more than 20% of the rows (or blocks) are going to be accessed by a SQL statement, the CBO prefers to do a full-table scan operation instead of using any indexes. Oracle feels they can read up the data faster using multi-block read-ahead and large reads than using an index and hopping around a lot doing single-block reads.
So, the less frequently a data item appears in a table, the better the candidate it is for an index.
Let’s explore this a bit more. The column ‘DENSITY’ stored along with the other table stats in USER_TABLES illustrates how often a data item appears in the table. The closer to zero, the better the candidate is for an index.
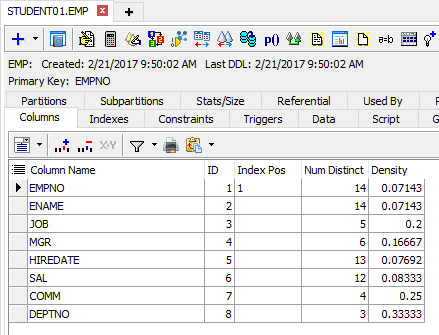
Toad Column Information
This is the columns panel of an F4 describe of the EMP table. I used the ‘show/hide columns’ button (left column header) to hide the columns I didn’t need for this illustration.
The num distinct (number of distinct values) and the density are useful numbers to decide if a column would make good use of an index.
The more unique the values, the better the candidate. The closer to zero the density is, the better the candidate as well.
So, in this illustration, JOB, COMM, and DEPTNO would be poor candidates for an index. EMPNO, ENAME, SAL, and HIREDATE are good candidates to index.
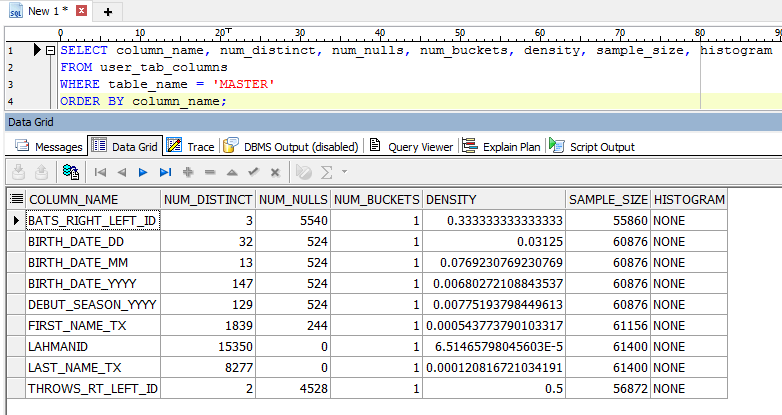
Table Column Statistics
SELECT column_name, num_distinct, num_nulls, num_buckets, density, sample_size, histogram
FROM user_tab_columns
WHERE table_name = 'MASTER'
ORDER BY column_name;
This is a script that shows similar information, useful if you want this kind of information from within a script or program.
In this example, the date columns would be good index candidates as would be FIRST_NAME_TX and LAST_NAME_TX. Poor choices for an index would be THROWS_RT_LEFT_ID (half the rows are 1 value, half another), LAHMANID, and BATS_RIGHT_LEFT_ID.
Take note of the number of null values. Oracle10 supports indexes that store null values. If you don’t use this syntax, nulls are not stored in the index and you will get a full table scan if your users ask for ‘AND <column name> IS NULL’…
CREATE INDEX EMP_COMM ON EMP(COMM,0);
Check out my blog on this exact topic for more details.
Index Tip 2
Use good coding techniques and know how your users are accessing the data.
Coding style affects index usage greatly. Instead of adding a function-based index, consider just reworking your WHERE clause items just a bit.
For example…
WHERE COMM * 1.1 > 1000 will not use an index on the COMM field; this code will: WHERE COMM > 1000/1.1.
WHERE NOT (SAL > 1000) will not use an index on the SAL field; this code will: WHERE SAL < 1000.
WHERE ENAME LIKE ‘%S%’ will not use an index on the ENAME field; this code will: WHERE ENAME LIKE ‘S%’.
The last example is more of end user training. When using the LIKE syntax, to use an index, you have to start with some values, not the global character.
Index Tip 3
Know your indexing options
There are several options that can be used when creating indexes. Some of these have been automatically incorporated into the CREATE INDEX syntax now but maybe some of you are still supporting older Oracle databases.
CREATE INDEX EMP_DEPTNO ON EMP(DEPTNO) <option>;
The first option I want to discuss is ‘NOLOGGING’. This feature allows for indexes to be created twice as fast. As you are creating an index, Oracle is journaling the changes made to the index blocks. But why? There is no syntax to restart a failed index build in the middle of its build, you have to start completely over when you solve the issue of why the index wouldn’t build in the first place. So, why journal the changes? This feature will create an index twice as fast and not journal the changes. It cannot be used when working with data guard and other features that depend upon this journaling to perform their tasks but it is great for test and QA environments to quickly prepare for a test!
The next option has since been incorporated into Oracle10. This option is ‘COMPUTE STATISTICS’. This feature collects statistics while the index is being built so you don’t have to run DBMS_STATS on the newly created index when done. My fingers used to just always type this but starting with Oracle10, the option is redundant, Oracle10 always collects statistics on indexes when creating or rebuilding them. IF you are collecting stats using DBMS_STATS package after an index build, stop the practice…save some time/computer time too.
Use the COMPRESS on all multiple key indexes. This will do a reverse compression on the keys per leaf block. If there is a lot of commonality in key values, you should get fewer leaf blocks which will mean faster index Range Scan operations. There is no real downside to this option. It takes far longer to do an additional I/O operation than to uncompress key values.
I’ve had issues with the final option I wish to discuss, called NOSORT. IF your data is already in sequence by the key value of the index, you can greatly speed up the index creation by skipping the sort process. However, where I’ve run into problems is if data is not in order, the index create fails. My data was usually just slightly out of sequence, I thought I was saving a lot of processing time but all I was doing was wasting my time. Using this option, if you can, will greatly shorten index create time.
Index Tip 4
Rebuild indexes when there are more than 10% change to the data in the underlying table. By the way, adding rows is also a DML operation! Unless the data is in the same order and the index key field, inserting rows will cause additional index leaf blocks as well.
I’m a big believer in keeping indexes rebuilt. Rebuilding indexes where the data changes keeps the leaf blocks full and your execution plan Range Scans shorter (fewer I/O operations).
If you never rebuild indexes, this kind of performance issue (for example) creeps up on you: One week, a query is running for 10 seconds. Two weeks later, after lots of updates to the table data, the same query runs for 12 seconds. Next month, it runs for 14 seconds, etc.
Why does this happen? Because indexes are maintained in sequence and an UPDATE operation is a delete and an add…leaving gaps in one area and maybe causing leaf block splits in another (additional I/O operations when doing Range Scan operations).
So…if you have tables where the data changes somewhat frequently, rebuild the indexes associated with that table weekly. If you have data that changes in some tables occasionally, rebuild the indexes associated with those tables monthly.
ALTER INDEX <index name> REBUILD <ONLINE>;
This will rebuild the index in place and push all the empty leaf blocks to the right hand side. Oracle12 maybe dropping these empty blocks; I need to confirm this. So the only time I drop and recreate indexes is if I am purging a lot of data. You don’t want to leave a lot of empty leaf blocks if your applications might be doing execution plan step ‘Fast Full Scan’ on indexes.
The ONLINE option allows for the current index to be used during the rebuild operation.
declare
cursor c_ui is
select index_name
, status
from user_indexes
where status <> 'USABLE'
and status <> 'VALID'
and status <> 'N/A';
begin
for r_ui in c_ui loop
execute immediate ' alter index '||r_ui.index_name||' rebuild ';
end loop;
end;
The above script is useful to get all the indexes associated with a table. This will rebuild ALL indexes associated with a table. I have seen too many DBAs do their rebuilds from existing scripts. If you don’t keep your script maintained, you might miss rebuilding newer indexes. I used to be a bad one for using existing scripts to do my work. SQL creating SQL is a much better practice and this script works great with its ‘execute immediate’ technology.
DO ADD a WHERE clause to select the table or tables of interest! This script will rebuild all indexes for a particular user.
It gets better than this. If you are a DBA type and are really unaware of which tables are getting a lot of DML operations (insert/update/delete), Oracle will tell you! Again, starting with Oracle10, there is a STALE feature associated with tables. I think this goes back to Oracle8i but you had to turn on monitoring manually. Oracle10 monitors all tables/indexes/etc. for AWR (automated workload repository).
USER_TAB_STATISTICS View
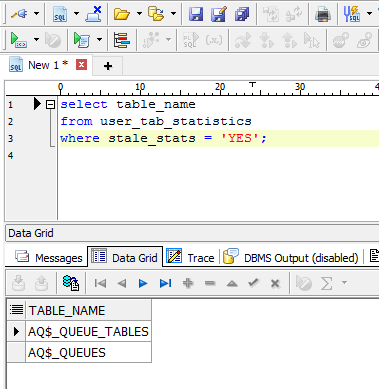
Query Showing Stale Stats
IF the STALE_STATS is ‘YES’, then there have been more than 10% change to the table, and all of the associated indexes should be rebuilt.
Blend this information in with the above PL/SQL script to automatically
Index Tip 5
Always add foreign key indexes.
One final quick Index tip…I always add an index on the foreign key columns. This helps Oracle with locking but also should help your applications. Primary/foreign key relationships are usually used in combination, looking up the parent row in the primary and using the foreign key to look up the related children rows.
I have blogged before on how Oracle selects indexes, when there are several to choose from. Click here to see my blog on index clustering factor…and how this plays out for index selection. You also don’t want too many indexes. While testing, always make sure your index you are adding is actually going to be used (click here for more details on too many indexes).
Dan Hotka
Author/Instructor/Oracle Expert
Start the discussion at forums.toadworld.com