Hi,
I have a lot of knowledge about how Oracle’s indexes work. I’ll start with how Oracle B-tree indexes work, as well as syntax and practical uses for each.
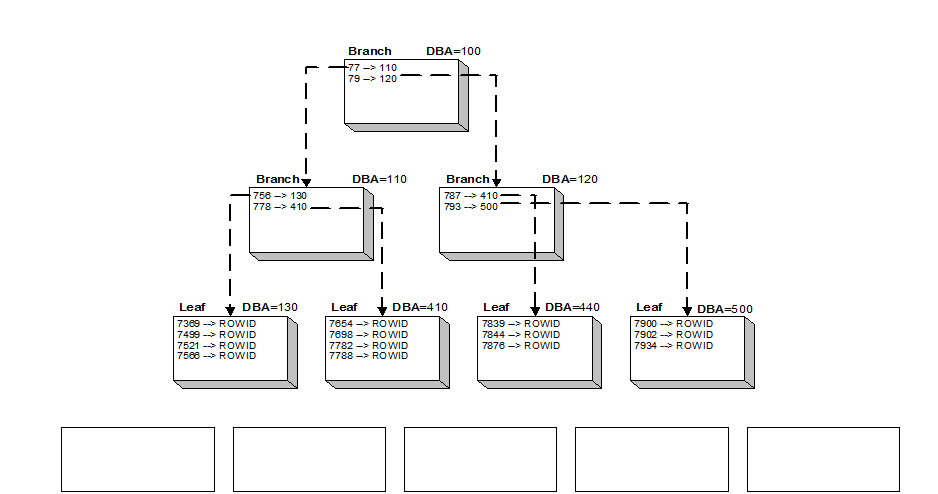
Oracle B-Tree Index Structure
The above illustration shows a single index. The empty boxes across the bottom represent the associated table’s blocks that the index pointers point to.
How Indexes Work
B-Tree indexes resemble an upside-down tree. This index has a HEIGHT of three. Generally, when this CBO statistic changes, it’s time to reorganize the index because another branch level has been added (another I/O to process the index). I’ll cover a better way to know when to reorganize indexes in a possible Index Tips and Techniques article.
The index is maintained in sequence by key value. There is no PCTUSED storage clause with an index. You can specify this parameter in the create storage clause but it is simply ignored. If there is not room in an index leaf block for an additional key value where it needs to go sequentially, then the leaf block is split into two, half the rows in one leaf, the rest in the other and the row is inserted in sequence.
The block addresses are called DBA or database block address. These are physical locations within the file that this index resides in. DBAs contain File# and Block #. The file# is the physical database file, block# is the block the data is in (i.e., offset from the beginning of the file). Using the DBA_EXTENTS view, you can see which object the DBA address is associated with.
The leaf blocks each point to the next and prior leaf blocks within the proper sequence. This gives the index a logical order even though the leaf blocks themselves might be stored all over the assigned disk. This allows Oracle to range scan, do descending searches, etc.
A unique lookup passes through the branch levels to the leaf block and finds the individual value it seeks. Each key value has a ROWID. ROWID is the unique and physical location of the row in the table blocks.
Range scan explain plan operations pass through the branch levels to find the first value in the range, then read across the leaf blocks until the range is satisfied.
Full scans and fast full scans explain plan operations just read the leaf blocks, do not read down through the branch levels. Full scans dosingle block reads and fast full scans use multi-block reads.
ROWID contains object#, file#, block#, and row# where file# is the physical database file, block# is the block the data is in, and row# is a pointer to a table within the block (covered in my performance tuning courses). This is a very clever design on Oracle’s part. This feature of finding blocks makes the Oracle database very portable across the hardware platforms it supports. You can use the DBMS_ROWID package to interpret this ROWID into readable numbers.
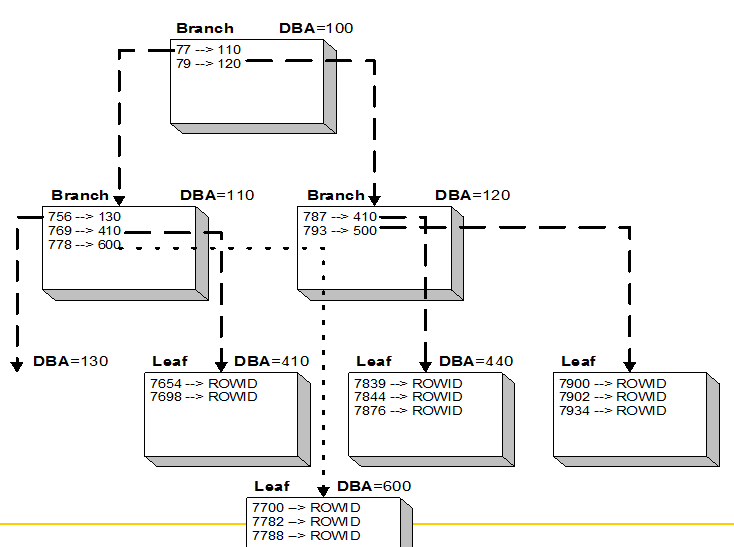
B-Tree Index Split
An update simply inserts a row in the leaf block, an update deletes the old key value row reference and inserts a new row with the new key value, and a delete operation just deletes the key value row reference.
During an insert operation, remember, indexes are maintained in sequence. IF there is not room in the leaf block for the row that is being added (either from an INSERT or an UPDATE operation), then the leaf block is split into two leaf blocks, the prior and next DBA leaf block addresses are updated, and half of the rows are put in one leaf block and the other half in the new leaf block. Upside here is this does not take that long to do, but it is extra transaction and archive work for the Oracle RDBMS. Downside is that these splits are generally not good for performance because it is another physical I/O process to read both half-empty leaf blocks.
*** Tips *** I recommend that the DBA staff reorganize indexes (not more often than once a week) on tables with a lot of DML. This will realign the index leaf blocks with the assigned PCTFREE.

Index Syntax
Non-Unique index is a regular B-tree index. It can contain repeating key values.
Unique index allows only for single occurrences of the indexed value. These are automatically created for you when you specify a primary key. Oracle11 now allows for you to give this primary key index a name during creation!
Reverse-key index reverses the key value before storing it in the B-tree structure. This is good for better insert throughput, especially when the key field is sequential in nature and there are a lot of users doing data entry. The better performance is because locking is spread out across the leaf structure instead of just the newest leaf block. Primary keys are typically in sequence. By using the reverse feature, the key values are no longer in sequence but in sequence by the reversed nature of the number. I have a fun ‘lucky breaks’ story that goes with this topic as well.
*** Note *** Oracle does not range scan on reverse-key indexes as the key values are no longer back to back in the leaf block.
Descending indexes store the values in a high-to-low sequence and are good for descending sorts and less-than operations.
/**********************************************************
* File: Function_Indexes.sql
* Type: SQL*Plus script
* Author: Dan Hotka
* Date: 10-20-2010
*
* Description:
* SQL*Plus script to display Function based Indexes
*
* Modifications:
*
**********************************************************/
set linesize 120
column USER format a15
column table_name format a20
column index_name format a30
column column_expression format a25
SELECT USER, TABLE_NAME, INDEX_NAME, COLUMN_EXPRESSION
FROM DBA_IND_EXPRESSIONS
WHERE INDEX_OWNER = USER;

Output from above script
Function-based indexes are good when using functions in the WHERE clause cannot be avoided. Examples include name lookups where the data could be in lower case/upper case/or a mix of cases. This index would help when you put an UPPER or LOWER function on the where clause column reference.
***Note*** You can use function-based indexes only on columns where there is a one-to-one relationship between the rows in the leaf block and the rows in the underlying table. This includes UPPER and LOWER functions for sure but does not work for anything from a GROUP BY clause for example.
SUMMARY
Watch for an article on Index Tips and Techniques. In this article, I’ll finish the topic of indexes with more practical uses for each as well as how to set and monitor the index storage parameters (mostly PCTFREE). I’ll give some practical advice on when and why indexes should be reorganized, and which indexes need to be reorganized.
I hope you find this information useful in your day-to-day use of the Oracle RDBMS.
Dan Hotka
Author/Instructor/Oracle Expert
Start the discussion at forums.toadworld.com