Companies have so much data that they will never use it all—to enhance business decisions, to build new markets, or to reach people they need to reach for their products or services. Yet, analysis of data is the number one reason that companies are adding new applications. The desire and need is there to use available data. Analysis that can lead to true marketing, product, and strategic directions—never thought possible—depends upon both structured and unstructured data.

Structured vs. Unstructured Data Infographic
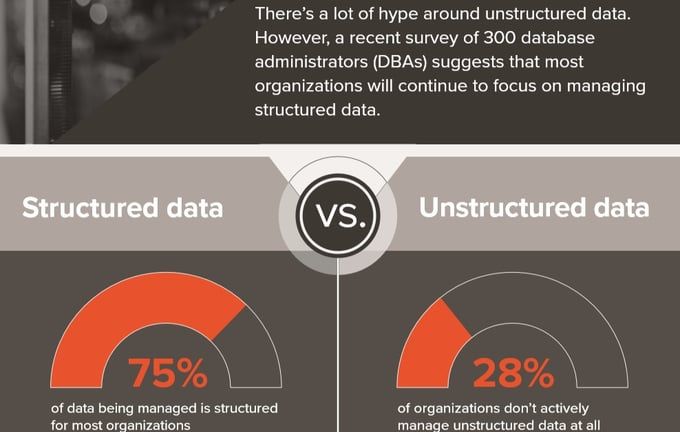
Make sure you take a look at the entire infographic, especially the sections about analytics and data. While other sections are noteworthy, this blog will explore the differences between structured and unstructured data, and reasons that structured data is still going to take the majority of DBA’s time in the foreseeable future.
According to the study that resulted in the infographic above, nearly three-fourths of corporate data is structured data. What that really means, I think, is that the majority of data that has beenharnessed (stored someplace in a useful form with query and processing mechanisms available to use it productively within the organization) is structured data.
Overall, however, more than 80% of data generated today is considered unstructured, "Structured vs Unstructured Data – What's the Difference?“, Devin Pickell, G2.3 That means that there is a lot of unstructured data that hasn’t been made useful yet.3
So, what is the difference between structured data and unstructured data, exactly? What is the importance of each of these types of data? And if unstructured data is underused for analytic purposes, that are apparently (according to the infographic and its supporting study) growing in importance, why are DBAs spending so much of their time with structured data and not managing critical unstructured data? Let’s examine those questions and their possible answers now.
Let’s define structured data and how it differs from unstructured data
Structured data is organized and formatted for relational databases, generally. It’s designed to be searchable in predictable ways based on the data’s organization in the database. Unstructured data is not that. It has not format or organization that can really be predicted or pre-defined. So, unstructured data use (collection, access, and analysis) is more difficult.

Structured data can be thought of as quantitative data. Since it has a predictable format, pieces of the data fit into fields or columns for orderly identification and access whether the data is housed in a relational database or a spreadsheet or somewhere else.
Here are some examples of structured data:
- Name
- Address
- Account Number
- Order Amount
- Price
- Inventory Count
Unstructured data is generally qualitative, with no predictable data organization, and so is stored differently—in formats that make using structured data access and analytic tools impossible. Unstructured data will require non-relational or NoSQL (“not only” SQL) data storage platforms. Data lakes are great for this, where data can be collected and quickly stored in its raw form, without the need for structural design for data that’s been processed for pre-designed reasons, and without needing to know what questions will need to be answered in the future. Some kind of inventory and analysis of the data will have to take place, but the idea is that the unstructured data may unlock all sorts of answers for the business once the means of finding trends in the data, for example, are found.

Here are some examples of unstructured data:
- Video clips
- Mobile device activity
- Social media usage
- Textual documents
- Images
Why are DBAs expected to still spend so much of their time with structured data, and not unstructured data?
The access method, or language, for structured data is SQL (structured query language). Then, analysis can be done on the result sets of SQL queries. That analysis might include finding patterns and trends about something important to the business (sales, customers, costs, etc.).
The fact is that the skills in most organizations today are skewed toward managing structured data, although it takes some programming to get to the data. Unstructured data access needs new methods, new algorithms. It’s in emails, Word documents, PDFs, videos, images, etc., not in a relational database where SQL queries can access it
Processing the data is very different between structured and unstructured data, and processing is already in place for structured data. To process unstructured data, systems need to access the data using a key (a reference point). If a photograph of Joe Smith is stored someplace, the “key” is likely going to be something that includes “Joe Smith.” Once found, the system then needs to access the entire data object—the photo of Joe Smith.
Structured data about Joe Smith would be stored neatly in columns like address and phone number. There is much more data stored in a photo of Joe than that structured row of fixed data elements, so there is a lot more data to store and more processing is needed to find the data of interest.
Within organizations that want to exploit unstructured data, some kind of asset management system will be very helpful in keeping track of software that will process those unstructured data, hardware capacity, and maintenance to schedule. “Big Data” analytics combinations of structured and unstructured data that must tie together should be documented somehow. All of this will be new to most organizations who are taking the steps necessary to make use of accumulated unstructured data.
A big challenge facing IT in organizations that are trying to build and use analytics platforms is ingesting data into them. One CIO at a Midmarket CIO Forum said, “Our biggest problem in IT is how do we get data into <the analytics system>. That’s where these things are really a pain, “Big data’s biggest problem: It’s too hard to get the data in,” Jason Hiner, ZDNet.1
That is backed up by data from a study by data integration specialist Xplenty which found that, “business intelligence professionals spend 50% to 90% of their time cleaning up raw data and preparing to input it into the company’s data platforms. That probably has a lot to do with why only 28% of companies think they are generating strategic value from their data.”1
While these BI professionals are likely not DBAs, the subject of this post, the data cleansing problem does point to a scaling problem in organizations, and limits the potential of big data, if key professional data people are spending a lot of their time doing mind-numbing sorting and organizing of data sets before they ever get analyzed. And this is only going to get worse as the sheer volume of data grows.1
The potential of unstructured data, or big data combined with structured data, will be realized faster if: 1) analytics software does data cleansing better, 2) data preparers become the paralegals of data science (this is already happening to a degree – see this TechRepublic article, “Is 'data labeling' the new blue-collar job of the AI era?” Hope Reese, TechRepublic2. 3) artificial intelligence helps cleanse data, with algorithms written to clean, sort, and categorize the data—but as evidence of how hard that is to do, Microsoft, IBM, and Amazon all invest in using people to do data prep and labelling that software can’t handle.2
Why is knowing all this about structured and unstructured data important?
We’ve now defined what structured and unstructured data are, and how they differ. For planning over the next few years (planning things like staffing, training, and technical infrastructure) it’s important to realize that structured data is not going away. Structured data requires management, just as it always has, especially since it still forms the bedrock of information that businesses run on (see the white paper, The real world of the database administrator).
Will unstructured data continue its climb up the priority ladder? You bet. But DBA management and CIOs are going to have to figure on keeping skills in managing structured data at nearly the levels they are right now into the next few years. And it’s very unclear just how DBA roles will evolve in the very new world of unstructured and big data.

Tips and reminders about structured data and the DBA’s role
Here are a few key points to take away from the study, the infographic, and what I’ve written in this post:
- Organizations run on structured data.
- IT professionals are used to structured data.
- Although there is a lot of unstructured data stored in all organizations, it’s not yet to the point of being managed.
- Analytics applications/platforms, to use anything but structured data, need to be more fully developed and understood, and organizations have to figure out what “management” of them means.
- As your organization delves deeper into unstructured data and its uses, begin to build skills into your DBA team to help the organization take advantage of unstructured data and find insights from it. The role of the DBA will evolve. All while keeping skills for managing structured data, of course.
Need help managing data?
Structured data continues to grow could easily consume all of your time. Quest Software is here to help you simplify complexity, reduce cost and risk, and drive performance. Maybe that’s why we’re consistently voted #1 by DBTA readers and have 95%+ customer satisfaction rate.
Toad® database management tools are cross-platform solutions from Quest® that can help new and veteran DBAs, and even “accidental” DBAs manage data in Oracle, SQL Server, DB2, SAP, MySQL, and Postgres environments.
Learn more about how Toad database management tools from Quest can help with database development, performance monitoring and database DevOps.
Visit Toad World® often for free advice via our blogs, free interactive help via our forums and free trial downloads.
Share on social media
If you think your colleagues would benefit from this article, share it now on social media with the buttons located at the top of this blog post. Thanks!
Start the discussion at forums.toadworld.com