Data warehouse assembles data dispersed in various data sources across the enterprise and helps business stakeholders manage their operations by making better informed decisions. Most organizations have multiple data stores: relational databases, spreadsheets, mainframes, mail systems or even paper files. Each of these data stores tends to serve a subset of the enterprise. Data warehouse attempts to overcome this limitation by combining all relevant data and by allowing managers to view their business from many different angles.
Before building a data warehouse you should become familiar with the terminology used to describe various parts of the warehouse.
Data Warehousing – Dimensions & Measures and Related Concepts
Each data warehouse consists of dimensions and measures. Dimensions allow data analysis from various perspectives. For example, time dimension could show you the breakdown of sales by year, quarter, month, day and hour. Product dimension could help you see which products bring in the most revenue. Supplier dimension could help you choose those business partners who always deliver their goods on time. Customer dimension could help you pick the strategic set of consumers to whom you'd like to extend your very special offers.
Measures are numeric representations of a set of facts that have occurred. Examples of measures include dollars of sales, number of credit hours, store profit percentage, dollars of operating expenses, number of past-due accounts and so forth.
Additive measures are measures that can be added across all dimensions. For example dollars of sales can be added across all dimensions within a retail store warehouse.
Semi-additive measures are measures that can be added across some, but not all dimensions. For example the bank account balance is simply a snapshot in time and cannot be summed over time. However you could add multiple accounts of the same customer to get the total balance for that customer.
Non-additive measures are measures that cannot be added across any dimensions. For example the inventory is simply a snapshot in time and cannot be summed over time. Nor can you combine inventory for various products.
Hierarchy defines parent-child relationships among various levels within a single dimension. For instance in a time dimension, year level is parent of four quarters, each of which is a parent of three months, which are parents of 28 to 31 days, which are parents of 24 hours. Similarly in a geography dimension a continent is a parent of countries, country could be a parent of states, and state could be a parent of cities.
Level is a column within a dimension table that could be used for aggregating data. For example, product dimension could have levels of product type (beverage), product category (alcoholic beverage), product class (beer), product name (miller lite, budlite, corona, etc).
Member is a value within a dimension level that can be used for aggregating and reporting data. For example each product category such as beverage, non-consumable, food, clothing, etc is a member. Each product class such as beer, wine, coke, bottled water would represent a member.
Data Mart is a subset of the data warehouse typically serving a functional area such as marketing or finance, or particular location of the business (for instance mid-Western division).
Data Warehousing – Fact and Dimension Tables
Data warehouses are built using dimensional data models which consist of fact and dimension tables. Dimension tables are used to describe dimensions; they contain dimension keys, values and attributes. For example, the time dimension would contain every hour, day, week, month, quarter and year that has occurred since you started your business operations. Product dimension could contain a name and description of products you sell, their unit price, color, weight and other attributes as applicable.
Dimension tables are typically small, ranging from a few to several thousand rows. Occasionally dimensions can grow fairly large, however. For example, a large credit card company could have a customer dimension with millions of rows. Dimension table structure is typically very lean, for example customer dimension could look like following:
Customer_key
Customer_full_name
Customer_city
Customer_state
Customer_country
Although there might be other attributes that you store in the relational database, data warehouses might not need all of those attributes. For example, customer telephone numbers, email addresses and other contact information would not be necessary for the warehouse. Keep in mind that data warehouses are used to make strategic decisions by analyzing trends. It is not meant to be a tool for daily business operations. On the other hand, you might have some reports that do include data elements that aren't necessary for data analysis.
Most data warehouses will have one or multiple time dimensions. Since the warehouse will be used for finding and examining trends, data analysts will need to know when each fact has occurred. The most common time dimension is calendar time. However, your business might also need a fiscal time dimension in case your fiscal year does not start on January 1st as the calendar year.
Most data warehouses will also contain product or service dimensions since each business typically operates by offering either products or services to others. Geographically dispersed businesses are likely to have a location dimension.
Fact tables contain keys to dimension tables as well as measurable facts that data analysts would want to examine. For example, a store selling automotive parts might have a fact table recording a sale of each item. The fact table of an educational entity could track credit hours awarded to students. A bakery could have a fact table that records manufacturing of various baked goods.
Fact tables can grow very large, with millions or even billions of rows. It is important to identify the lowest level of facts that makes sense to analyze for your business this is often referred to as fact table "grain". For instance, for a healthcare billing company it might be sufficient to track revenues by month; daily and hourly data might not exist or might not be relevant. On the other hand, the assembly line warehouse analysts might be very concerned in number of defective goods that were manufactured each hour. Similarly a marketing data warehouse might be concerned by the activity of a consumer group with a specific income-level rather than purchases made by each individual.
Data Warehousing – Star and Snowflake Schemas
The foundation of each data warehouse is a relational database built using a dimensional model. A dimensional model consists of dimension and fact tables and is typically described as star or snowflake schema.
Star schema resembles a star; one or more fact tables are surrounded by the dimension tables. Dimension tables aren’t normalized – that means even if you have repeating fields such as name or category no extra table is added to remove the redundancy. For example, in a car dealership scenario you might have a product dimension that might look like this:
Product_key
Product_category
Product_subcategory
Product_brand
Product_make
Product_model
Product_year
In a relational system such design would be clearly unacceptable because product category (car, van, truck) can be repeated for multiple vehicles and so could product brand (Toyota, Ford, Nissan), product make (Camry, Corolla, Maxima) and model (LE, XLE, SE and so forth). So a vehicle table in a relational system is likely to have foreign keys relating to vehicle category, vehicle brand, vehicle make and vehicle model. However in the dimensional star schema model you simply list out the names of each vehicle attribute.
Star schema also contains the entire dimension hierarchy within a single table. Dimension hierarchy provides a way of aggregating data from the lowest to highest levels within a dimension. For example, Camry LE and Camry XLE sales roll up to Camry make, Toyota brand and cars category. Here is what a star schema diagram could look like:
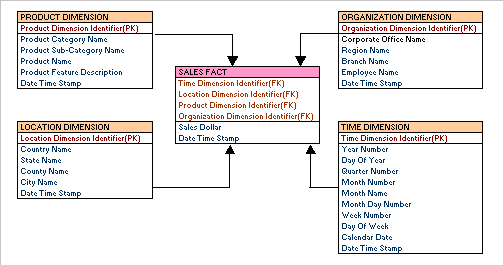
Notice that each dimension table has a primary key. The fact table has foreign keys to each dimension table. Although data warehouse does not require creating primary and foreign keys, it is highly recommended to do so for two reasons:
- Dimensional models that have primary and foreign keys provide superior performance, especially for processing Analysis Services cubes.
- Analysis Services requires creating either physical or logical relationships between fact and dimension tables. Physical relationships are implemented through primary and foreign keys. Therefore if the keys exist you save a step when building cubes.
Snowflake schema resembles a snowflake because dimension tables are further normalized or have parent tables. For example we could extend the product dimension in the dealership warehouse to have a product_category and product_subcategory tables. Product categories could include trucks, vans, sport utility vehicles, etc. Product subcategory tables could contain subcategories such as leisure vehicles, recreational vehicles, luxury vehicles, industrial trucks and so forth.
Snowflake schema generates more joins than a star schema during cube processing, which translates into longer queries. Therefore it is normally recommended to choose the star schema design over the snowflake schema for optimal performance. Snowflake schema does have an advantage of providing more flexibility, however. For example, if you were working for an auto parts store chain you might wish to report on car parts (car doors, hoods, engines) as well as subparts (door knobs, hood covers, timing belts and so forth). In such cases you could have both part and subpart dimensions, however some attributes of subparts might not apply to parts and vise versa. For example, you could examine the thread size attribute would apply to a tire but not for nuts and bolts that go on the tire. If you wish to aggregate your sales by part you will need to know which subparts should rollup to each part as in the following:
Dim_subpart
subpart_key
subpart_name
subpart_SKU
subpart_size
subpart_weight
subpart_color
part_keyDim_part
part_key
part_name
part_SKU
With such a design you could create reports that show you a breakdown of your sales by each type of engine, as well as each part that makes up the engine.
Data Warehousing – Indexing Considerations
In addition to the dimensional model, data warehouses built using SQL Server will also contain Analysis Services cubes. Analysis Services offers multi-dimensional storage for data and aggregations. Queries executed against Analysis Services cubes are typically considerably faster than similar queries executed against the dimensional database. However, there will be times when you will need to build reports that go against the dimensional database. For example, if you have very large dimensions with millions of rows you might not be able to take advantage of MSAS 2000. The problem is that Analysis Services loads all dimensions into memory at startup, and you're likely to limit Analysis Services to only 2GB of memory. If you have many large dimensions, the Analysis Services service might not even be able to start. With the above in mind you need to ensure that your dimensional database has all indexes necessary for performance optimization.
Even if you don't have very large dimensions, cube processing time might be affected dramatically by appropriate indexes on fact and dimension tables.
Dimension tables tend to have relatively few columns; therefore they usually have a few indexes. Most dimension tables can benefit from a primary key index. If the dimension is large and you must execute queries against the dimensional database you might also want to add a non-clustered index on each of the dimension levels that will be queried.
Fact tables usually have numerous foreign keys to dimension tables. During cube processing Analysis Services will issue a query that will join the fact table to each dimension table that is part of the cube. Therefore it is advisable to create an index all dimension keys within the fact table. Measure columns within fact tables are never joined to any other table and do not need to be indexed.
The clustered index within a fact table can be built on the combination of all dimension keys. Alternatively you might decide to add an identity column to the fact table and place the clustered index on it. A combination of all dimension keys can usually serve as a unique identifier of the fact table; but due to the nature of fact tables they don't really need primary keys. On the other hand, having a clustered index on the fact table can make a huge difference in queries executed during cube processing or during report generation.
Yet another indexing consideration is index maintenance. Although indexes are ordinarily considered part of the relational design they can make a big difference in reporting and cube processing queries. Fact tables tend to grow quickly; depending on your environment you could be adding thousands or million records daily. Doing so affects the index effectiveness because indexes tend to get fragmented as data is inserted, deleted or updated. Furthermore, since SQL Server must maintain indexes during data changes, having many indexes could also cause a negative effect on data load. Therefore, if possible we recommend dropping indexes (particularly the clustered index) on the fact table prior to large data loads and rebuilding indexes after the load is complete. Dimension tables typically don't grow very much daily. Therefore you can normally ensure optimal performance by rebuilding dimension table indexes occasionally.
Data Warehousing – Slowly Changing Dimensions
By nature of the data warehouse, fact and dimension tables are likely to have very different transactional activity. Fact tables will be mostly inserted into as you load data. Very infrequently you might have to update the facts that were loaded incorrectly. It is even less likely that you'll ever delete rows from the fact table; the only time this might happen is if you wanted to archive the old data that is no longer relevant for the current portion of the data warehouse. Dimension tables, on the other hand are likely to see frequent updates. A classic example of this is a consumer dimension which tracks people that buy your products or services. People can change names due to marriage, divorce or another reason, they can change their title of courtesy from Ms to Mrs or to Dr. As people age they also fit a different age group and perhaps even a different education and income level. Therefore you are likely to change dimension table values often.
Dimensions that are changing over time are referred to as slowly changing dimensions (SCD). There are several ways to handle SCD; most common approaches are referred to as type 1, type 2, type 3 and type 4.
The easiest way to manage SCD is to simply override the existing value with the new value type 1. Indeed if a department changes the title from "Finance" to "Financial" overwriting such a value isn't likely to do much harm. However, you must weigh the consequences of overriding existing values carefully to ensure that your reports don't lose credibility. For example, suppose Mr. Smith who has near perfect credit marries Ms. Jones who has recently declared bankruptcy. Since Mr. Smith had near perfect credit before his marriage your bank has issued him a loan for $200,000. If you overwrite Mr. Smith's credit score with his new, considerably lower credit score you will make decisions from the not very distant past look very incorrect. If your data analysts happen to run reports immediately before and immediately after the credit rating was changed your data warehouse credibility will be compromised. Here is what type 1 SCD records would look like before and after change:
| Customer_key | Customer_name | Customer_city | Customer_state |
|---|---|---|---|
| 123 | Ms. Brown | Houston | Texas |
| 123 | Mrs. Green | Houston | Texas |
As you can see type 1 SCD does not allow tracking of changes. Once you overwrite the value all historical reports will display Mrs. Green instead of Ms. Brown.
The second and more common way of handling SCD is to create a new record when dimension attributes change – type 2. For example, when Ms. Brown becomes Mrs. Green you create a new record for that customer and mark the first record as obsolete. The second approach adds effective date and obsolete date columns to dimension tables. Doing so allows a data warehouse architect to maintain a history of SCD changes. After a change occurs the warehouse will have the following two records (one of them marked as obsolete):
| Customer_key | Customer_name | Customer_city | Customer_state | Effective_date | Obsolete_date |
|---|---|---|---|---|---|
| 123 | Ms.Brown | Houston | Texas | 1/1/2000 | 1/1/2005 |
| 234 | Mrs.Green | Houston | Texas | 1/1/2005 | NULL |
The third approach is to add columns to the dimension tables in order to maintain the history of changes in a single row. In the case of consumer dimension you would create an old last name and current last name columns along with the date column that indicates when the change occurred. This type of auditing of changes is typically reserved for very few dimensions where change history tracking is critical. For example if your product prices tend to change over time and you must compare revenues based on old and new price then you might wish to use this method. Type 3 of maintaining SCD carries much overhead and is not used very frequently. After type 3 change the warehouse will still have a single record shown below:
| Customer_key | Customer_name | Customer_city | Customer_state | Change_date | Old_name |
|---|---|---|---|---|---|
| 123 | Mrs.Green | Houston | Texas | 1/1/2005 | Ms.Brown |
Most environments that use type 3 slowly changing dimensions track 2 iterations of changes; that is you would record the current version, previous version and version before last for the changed column.
Type 4 is a special way of handling type 2 changes. Type 2 usually tracks unlimited history by creating new records each time the change occurs. If you know how far back you wish to track history you can add logic to your code to delete any records that go too far back in history. For example, suppose we created an exam and offered it to our students. As time goes on we might decide to edit the exam. We could manage these edits using type 2 method, but if we accumulate 10 versions of the same exam the data might get confusing. So we might decide that we only store up-to 9 records per each exam; any time 10th version of an exam is created we'll delete the 1st version from the warehouse.
Data Warehousing – Extraction, Transformation and Loading
A data warehouse does not generate any data; instead it is populated from various transactional or operational data stores. The process of importing and manipulating transactional data into the warehouse is referred to as Extraction, Transformation and Loading (ETL). SQL Server supplies an excellent ETL tool known as Data Transformation Services (DTS) in version 2000 and SQL Server Integration Services (SSIS) in version 2005.
ETL resolves the inconsistencies in entity and attribute naming across multiple data sources. For example the same entity could be called customers, clients, prospects or consumers in various data stores. Furthermore attributes such as address might be stored as three or more different columns (address line1, address line2, city, state, county, postal code, country and so forth). Each column can also be abbreviated or spelled out completely, depending on data source. Similarly there might be differences in data types, such as storing data and time as a string, number or date. During the ETL process data is imported from various sources and is given a common shape.
In addition to the changes that you can manage in ETL relatively easily, there are some data inconsistencies that you might have to fix manually. For example, examine the following data values:
Dr. Jimmy Smith
James L. Smith, Jr.
Jim L Smith, M.D.
James Smith MD
Jim Smith, JR – M.D.
A human eye can easily suspect that all of these values could represent the same person. However unless you work with James Smith or his accounts you cannot be certain. Should you show each of these values as a separate person on your reports à Writing a program that can fix such data inconsistencies could be a challenge, whereas a data entry clerk that created these values might be able to change them to a single, correct value with minimal effort.
Data inconsistencies are commonplace in operational data sources that allow free form data entry. A data warehouse cannot fix problems with poorly designed operational systems, but it is likely to make such issues known to data analysts and business managers. Even if you design smart ETL logic to correct the existing issues predicting all future variations of "Doctor Jim L Smith Junior" is a daunting task. Instead you should attempt to fix the data entry applications to limit the human error.
In addition to importing data from various sources, ETL is also responsible for transforming data into a dimensional model. Depending on your data sources the import process can be relatively simple or very complicated. For example, some organizations keep all of their data in a single relational engine, such as SQL Server. Others could have numerous systems that might not be easily accessible. In some cases you might have to rely on scanned documents or scrape report screens to get the data for your warehouse. In such situations you should bring all data into a common staging area first and then transform it into a dimensional model.
The need for a staging database isn't limited to those warehouses that have inaccessible data sources. A staging area also provides a good place for assuring that your ETL is working correctly before data is loaded into dimension and fact tables. So your ETL could be made up of multiple stages:
- Import data from various data sources into the staging area.
- Cleanse data from inconsistencies (could be either automated or manual effort).
- Ensure that row counts of imported data in the staging area match the counts in the original data source.
- Load data from the staging area into the dimensional model.
Start the discussion at forums.toadworld.com