Oracle Text (formerly known as InterMedia Text and ConText) is a full text indexing functionality. With Oracle text indexes (also known as Domain index), we can index text documents and search it based on contents efficiently using text patterns with specialized text query operators. Oracle Text index differs from the traditional B-Tree or Bitmap indexes in a number of ways and there are several components which communicates internally to form a text index. In this article, I will try to present the architecture behind the processing of a Oracle text index to help us understand how a text index actually works.
Oracle Text Architecture
We create a Oracle text index by defining a set of preferences (options) for the text index before actually creating the index. These preferences determine, how to locate the documents (to be indexes) and how these documents should be processed and indexed by the Oracle text engine. The following diagram represents the architecture (framework) of a Oracle Text Index processing (creation) in Oracle 12c database, containing the different preferences that we can set for the index.
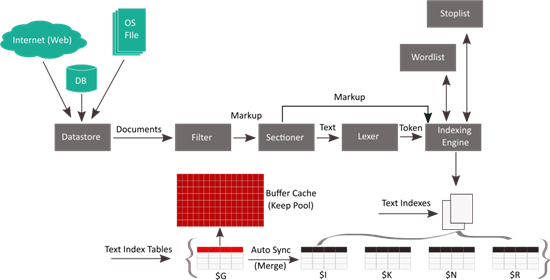
As stated earlier, Oracle Text index differs from the traditional B-Tree or Bitmap in a number of ways. In an Oracle Text index, the text data is not directly indexed rather, the text data is decomposed into a set of tokens (which are stored in database internal tables) and those tokens are indexed based on certain preferences that we define while creating a text index. Text search is performed using lookup into text token tables. Further, Oracle text index is not just limited to database table records, which means we can index text data coming from a number of data sources.
Let's walk through the different architectural components of a Oracle Text index to have a better understanding as to how a text index is created and processed. I will not go through the details of each and every options that can be set of a text index, rather I will try to provide a brief idea about what these option means.
DATASTORE
When we create a Text index, the first preference that we need to define is the source of the document. The DATASTORE preference of a Oracle Text index defines the source of the text document from where the documents should be streamed for indexing. With Oracle text indexes, we can index text documents coming from a variety of sources like database tables, server file system or even from the World Wide Web (WWW). While creating a Oracle Text index, the source of the text document is defined using any of the following values for the DATASTORE preference.
- DIRECT_DATASTORE: Indicates that the data is stored internally in text columns of a database table. Each row is indexed as a single document. This is the default datastore for a text index.
- MULTI_COLUMN_DATASTORE: Indicates that the data is stored in text table in more than one column. Columns are concatenated (joined) to create a virtual document and each concatenated row is indexed as a single document
- DETAIL_DATASTORE: Indicates that the data is stored internally in a text column. Document consists of one or more rows stored in a text column in a detail table, with header information stored in a master table
- NESTED_DATASTORE: Indicates that the data is stored in nested tables
- FILE_DATASTORE: Indicates that the data is stored in Operating System files. This type of data source is supported only for CONTEXT index. (more on that in the upcoming sections)
- URL_DATASTORE: Indicates that the data is stored over World Wide Web (WWW). This type of data source is supported only for CONTEXT index
- USER_DATASTORE: Indicates that the documents would be synthesized at index time by a user defined stored procedure
FILTER
Once the text document is streamed from the data store, it passes through a filter (as shown in the architectural diagram) before being indexed. In this phase the text stream can be converted to format that is recognized by the Oracle text processing engine. We must format documents of types such as Microsoft Word or PDF to text to be able to index them. Following are the different types of FILTER preferences that can be applied to a incoming text stream before being indexed.
- NULL_FILTER: Indicates that no filtering to be applied to the incoming text stream. Documents which are in text, HTML or XML formats do not need any filtering. This is the default FILTER preference for a text index.
- AUTO_FILTER: Automatically detects the format of the incoming documents and filters (converts) those to marked up text as well as convert the document character set to match the database character set.
- USER_FILTER and PROCEDURE_FILTER: We can create our own custom filter to filter the incoming text streams. The custom filter can be created externally which is executed from the file system or internally as PL/SQL procedure. To allow Oracle use external custom filter for a Text index we must use the USER_FILTER preference type. For internal PL/SQL filter we must use the PROCEDURE_FILTER preference type.
- CHARSET_FILTER:Oracle Text engine expects the incoming document stream to be in database character set. If the incoming stream is not in the database character set we can use the CHARSET_FILTER to convert the incoming document stream into database character set
SECTIONER
Once the incoming document stream is passed through the filter and the necessary conversions are applied, it goes through the Sectioner in the next phase. The task of the sectioner is to divide the incoming text stream into multiple sections based on the internal document structures (HTML or XML). Dividing the text stream into multiple sections helps in efficient text search by limiting the search to a specific section (with the help of WITHIN operator) in the document. A Sectioner is defined using the SECTION_GROUPS preference of Oracle text index and can have any of the following values.
- NULL_SECTION_GROUP: This is the default sectioner, which doesn't divide the incoming text stream into multiple sections.
- BASIC_SECTION_GROUP: We can use this section group for defining sections in the incoming text stream where the start and end tags are of the form <A> and </A>
- HTML_SECTION_GROUP: We can use this section group for dividing HTML document stream into sections.
- XML_SECTION_GROUP: We can use this section group for dividing XML document stream into sections.
- AUTO_SECTION_GROUP: We can use this section group to automatically create a zone section for each pair of start/end tags in a XML document.
- PATH_SECTION_GROUP: We can use this group type to index XML documents. This behaves like the AUTO_SECTION_GROUP. The difference is that with this section group we can also perform path searching with the INPATH and HASPATH operators.
- NEWS_SECTION_GROUP: We can use this section group for defining sections in newsgroup formatted documents according to RFC 1036 standards.
LEXER
Once the incoming document stream is divided into multiple sections (if specified) with the help of a sectioner, it passes through the LEXER in the next phase. A Lexer, basically determines the language associated with the incoming document. We have the following list of values for the LEXER preference that can be used to define the language of the incoming document stream.
- AUTO_LEXER : This type of Lexer automatically determines the language associated with the documents. We should use the AUTO_LEXER, if a table column contains documents of different languages.
- BASIC_LEXER: We can use the BASIC_LEXER preference type to index whitespace-delimited languages such as English, French, German, and Spanish. For some of these languages we can enable alternate spelling, composite word indexing, and base letter conversion. This is the default Lexer for a text index.
- MULTI_LEXER: We can use the MULTI_LEXER preference type for indexing tables containing documents of different languages such as English, German, and Japanese
- USER_LEXER : We can use the USER_LEXER preference type to create our own Lexer for indexing a particular language.
- WORLD_LEXER: We can use the WORLD_LEXER preference type for indexing tables containing documents of different languages and to auto detect the languages in the document.
Wordlist & Stoplist
Once the language associated with the incoming document stream is identified, the document (record) is ready for indexing by the Oracle text engine. However, before indexing the document, the text engine will use the STOPLIST preference to determine the words (tokens) that are not be indexed. The text engine will also use the WORDLIST preference to define how the the stemming (words with the same linguistic root), fuzzy matching (similarly spelled words) and wild card queries be handled.
We can create our own STOPLIST and WORDLIST; however, Oracle by default uses the BASIC_STOPLIST and BASIC_WORDLIST options for the STOPLIST and WORDLIST preferences respectively.
STORAGE
We may use the STORAGE preference of Oracle text index, to define how the text index needs to be stored in the database. The storage preference lets us define the tablespace and creation parameters of the internal database tables and indexes, that collectively constitutes a Oracle text index. Since a Oracle Text index is internally comprised of a set of tables and indexes, we can also set different storage characteristics for these internal tables and indexes with the help of the STORAGE preference.
Text Index Types
Oracle Text provides three types of indexes to cover all the text search needs. These are STANDARD, CATALOG, and CLASSIFICATION index types as described below.
- Standard (CONTEXT) index type is used for traditional full-text retrieval over large text documents (like Word, PDF, etc) and web pages (HTML). The CONTEXT index type provides a rich set of text search capabilities for finding the content we need, without returning pages having false results.
- Catalog (CTXCAT) index type is the first text index designed specifically for eBusiness catalogs. The CTXCAT catalog index type provides flexible searching and sorting at web-speed. This type of text index is best suited for indexing small fragments of texts that should be indexed with other relational data.
- Classification (CTXRULE) index type can be used for building document classification or routing applications. The CTXRULE index type is created on a table of queries, where the queries define the classification or routing criteria.
Oracle Text Index objects
Once all the preferences are defined and the document is indexed by the Oracle text engine, the text engine generates a set of database objects, which is collectively known as the Oracle Text index. Oracle Text index is generally (for CONTEXT and CTXRULE type) comprised of four tables referred to as $I, $K, $N and $R tables respectively. These tables have names concatenated from DR$, the name of the text index and the suffix (example $K).
- The $I table contains the actual data which is being indexed, which means all the tokens (words) generated from the text document is stored in this table. The tokens in this table are indexed by means of a B-Tree index with a name having format DR${index_name}$X.
- Each row in the table (containing text document) consists of a single DOCID/ROWID pair. The $K table maps the internal DOCID values to external ROWID values and it is a Index Organized table to facilitate efficient lookup.
- The $R table is designed for the opposite lookup from the $K table, i.e. fetching a ROWID when we know the DOCID value. The entries from this table are indexed by means of a B-Tree index with a name having format DRC${index_name}$R.
- The $N table contains a list of deleted DOCID values, which are cleaned up by the index optimization process. This table is created as an index organized table for efficient cleanup operation.
In addition to these tables, there are other tables like $P and $S which may get created based on the options used for creating the text index. Oracle 12c has introduced a new text index table suffixed with $G. This table is used to improvise the text index maintenance and performance and acts as a intermediary table for the $I and can be kept in memory (buffer cache) for improved performance. (More on this in an upcoming article)
How a text query is processed
There are two methods in which the kernel can query a text index as described below.
In the first and the most commonly used case, the kernel asks the text index for all the ROWIDs (returned in batches) that satisfy a particular text search. Oracle looks into the token table ($I table) which contains all the indexed tokens as well as the information about the ROW and WORD positions where the token appears in the document. However, the row information in the $I table is stored as internal DOCID values, which must be translated to the external ROWID values. The translation is done by performing a lookup into the $R table, which has the ROWIDs for all the respective DOCIDs. This method is known as indexed lookup.
In the second method, the kernel passes individual ROWIDs to the text index, and asks whether that particular ROWID satisfies a certain text criterion. Oracle looks into the token table ($I table) which has the information about the ROW and WORD positions where the token appears in the document. However, since the row information is stored in internal DOCID values, it needs to first find the DOCIDs for the individual ROWIDs that are passed to the text index. This is done by fetching the DOCIDs from the $K table, which has a mapping between the ROWIDs and DOCIDs. This type of lookup is commonly done where there is a very selective structured clause, so that only a few ROWIDs must be checked against the text index and is known as functional lookup.
Creating a Text Index
Before creating a Oracle text index, we should create all required preferences like DATASTORE, FILTER, LEXER, SECTION_GROUPS etc. which would be used by the intended Text index. We use the CTX_DDL.CREATE_PREFERENCE procedure to a create a preference. For instance, in the following example I am creating a DATASTORE preference to define the data store as the FILE_DATASTORE where the documents from file system /data/myapp/docs would be indexed.
---//
---// create preference example //---
---//
begin
ctx_ddl.create_preference('myapp_fds', 'FILE_DATASTORE');
ctx_ddl.set_attribute('myapp_fds', 'PATH', '/data/myapp/docs');
end;
We can use the CTX_DDL.SET_ATTRIBUTE procedure to set or modify different properties of a preference. For instance, in the above example we have used the SET_ATTRIBUTE procedure to set the PATH of the “myapp_fds” DATASTORE preference to point to file system path “/data/myapp/docs”.
However, we can use the following simplistic form of creating a text index and Oracle will automatically use all the DEFAULT preferences for the specific text index.
---//
---// simplistic create index statement for text index //---
---//
CREATE INDEX [schema.]index on [schema.]table(column) INDEXTYPE IS
ctxsys.context|ctxsys.ctxcat|ctxsys.ctxrule
;
Demonstration
Let's quickly go through a demonstration to understand what we have discussed so far. In the following example, I have a table called BLOG_DOCS which will store documents specifically in the field DOC_DATA which is a CLOB column and will contain the actual contents of the documents. I am going to create a CONTEXT index on this field so that we can efficiently search documents using text patterns.
---//
---// table to store documents //---
---//
SQL> create table blog_docs
2 (
3 doc_id number not null,
4 doc_title varchar2(25) not null,
5 doc_author varchar2(25) not null,
6 doc_data clob not null
7 );
Table created.
As mentioned earlier, we should create the text index preferences before creating a text index. However, if we choose to omit the preference creation, Oracle will create the text index with DEFAULT preference as in the following example.
---//
---// create CONTEXT index on doc_data //---
---//
SQL> create index blog_doc_txt_idx on blog_docs (doc_data)
2 indextype is ctxsys.context;
Index created.
We have a function/procedure called CTX_REPORT.CREATE_INDEX_SCRIPT that can be used to extract the DDL of a text index. If we look into the text index creation script, we could see that Oracle has created this text index with all DEFAULT preferences as shown below.
---//
---// extracting DDL of the created text index //---
---//
SQL> select ctx_report.create_index_script('MYAPP.BLOG_DOC_TXT_IDX') ddl from dual;
DDL
-------------------------------------------------------------------------------------------------
begin
ctx_ddl.create_preference('"BLOG_DOC_TXT_IDX_DST"','DIRECT_DATASTORE');
end;
/
begin
ctx_ddl.create_preference('"BLOG_DOC_TXT_IDX_FIL"','NULL_FILTER');
end;
/
begin
ctx_ddl.create_section_group('"BLOG_DOC_TXT_IDX_SGP"','NULL_SECTION_GROUP');
end;
/
begin
ctx_ddl.create_preference('"BLOG_DOC_TXT_IDX_LEX"','BASIC_LEXER');
end;
/
begin
ctx_ddl.create_preference('"BLOG_DOC_TXT_IDX_WDL"','BASIC_WORDLIST');
end;
/
begin
ctx_ddl.create_stoplist('"BLOG_DOC_TXT_IDX_SPL"','BASIC_STOPLIST');
end;
/
begin
ctx_ddl.create_preference('"BLOG_DOC_TXT_IDX_STO"','BASIC_STORAGE');
ctx_ddl.set_attribute('"BLOG_DOC_TXT_IDX_STO"','R_TABLE_CLAUSE','lob (data) store as (cache)');
ctx_ddl.set_attribute('"BLOG_DOC_TXT_IDX_STO"','I_INDEX_CLAUSE','compress 2');
end;
/
begin
ctx_output.start_log('BLOG_DOC_TXT_IDX_LOG');
end;
/
create index "MYAPP"."BLOG_DOC_TXT_IDX"
on "MYAPP"."BLOG_DOCS"
("DOC_DATA")
indextype is ctxsys.context
parameters('
datastore "BLOG_DOC_TXT_IDX_DST"
filter "BLOG_DOC_TXT_IDX_FIL"
section group "BLOG_DOC_TXT_IDX_SGP"
lexer "BLOG_DOC_TXT_IDX_LEX"
wordlist "BLOG_DOC_TXT_IDX_WDL"
stoplist "BLOG_DOC_TXT_IDX_SPL"
storage "BLOG_DOC_TXT_IDX_STO"
')
/
begin
ctx_output.end_log;
end;
/
Once the CONTEXT index is created, we can observe that the four text index tables namely $I, $K, $N and $R are created for the text index as shown below.
---//
---// internal text index tables created upon index creation //---
---//
SQL> select owner,table_name,iot_type from dba_tables
2 where owner='MYAPP' and table_name like '%BLOG_DOC%' order by table_name;
OWNER TABLE_NAME IOT_TYPE
--------------- ------------------------- ------------
MYAPP BLOG_DOCS
MYAPP DR$BLOG_DOC_TXT_IDX$I
MYAPP DR$BLOG_DOC_TXT_IDX$K IOT
MYAPP DR$BLOG_DOC_TXT_IDX$N IOT
MYAPP DR$BLOG_DOC_TXT_IDX$R
We could also observe that the data from $I (tokens) and $R (ROW_NO) tables are indexed by means of B-Tree indexes as found below.
---//
---// B-Tree indexes on $I and $R tables //---
---//
SQL> select owner,index_name,table_name,index_type from dba_indexes
2 where index_name like '%BLOG_DOC_TXT_IDX%';
OWNER INDEX_NAME TABLE_NAME INDEX_TYPE
--------------- ------------------------- ------------------------- ---------------------------
MYAPP DR$BLOG_DOC_TXT_IDX$X DR$BLOG_DOC_TXT_IDX$I NORMAL
DRC$BLOG_DOC_TXT_IDX$R DR$BLOG_DOC_TXT_IDX$R NORMAL
BLOG_DOC_TXT_IDX BLOG_DOCS DOMAIN
---//
---// indexed columns from $I and $R tables //--
---//
SQL> select INDEX_OWNER,INDEX_NAME,TABLE_NAME,COLUMN_NAME,COLUMN_POSITION from dba_ind_columns
2 where INDEX_NAME in ('DR$BLOG_DOC_TXT_IDX$X','DRC$BLOG_DOC_TXT_IDX$R')
3 order by 2,5;
INDEX_OWNER INDEX_NAME TABLE_NAME COLUMN_NAME COLUMN_POSITION
--------------- ------------------------- ------------------------- --------------- ---------------
MYAPP DR$BLOG_DOC_TXT_IDX$X DR$BLOG_DOC_TXT_IDX$I TOKEN_TEXT 1
TOKEN_TYPE 2
TOKEN_FIRST 3
TOKEN_LAST 4
TOKEN_COUNT 5
DRC$BLOG_DOC_TXT_IDX$R DR$BLOG_DOC_TXT_IDX$R ROW_NO 1
Now, if we describe the tables, we could notices that the $I table will contain all the tokens (TOKEN_TEXT) generated by decomposing the text record (document) as well as the information (TOKEN_INFO) about the ROWNO and WORD positions in the text document where these token appears.
---//
---// $I tables contains indexed tokens //---
---//
SQL> desc DR$BLOG_DOC_TXT_IDX$I
Name Null? Type
----------------------------------- -------- ------------------------
TOKEN_TEXT NOT NULL VARCHAR2(64)
TOKEN_TYPE NOT NULL NUMBER(10)
TOKEN_FIRST NOT NULL NUMBER(10)
TOKEN_LAST NOT NULL NUMBER(10)
TOKEN_COUNT NOT NULL NUMBER(10)
TOKEN_INFO BLOB
The $K table will contain mapping entries for each DOCID/ROWID pair i.e. for each text record (from the table being indexed) there will be an entry in this table mapping the records DOCID with that of the physical ROWID (TEXTKEY).
---//
---// $K table maps DOCID width ROWID //---
---//
SQL> desc DR$BLOG_DOC_TXT_IDX$K
Name Null? Type
----------------------------------- -------- ------------------------
DOCID NUMBER(38)
TEXTKEY NOT NULL ROWID
The $R table will contain the ROWIDs in internal format for all the DOCIDs in the table.
---//
---// $R table is used for opposite lookup for $K table //--
---//
SQL> desc DR$BLOG_DOC_TXT_IDX$R
Name Null? Type
----------------------------------- -------- ------------------------
ROW_NO NOT NULL NUMBER(3)
DATA BLOB
The $N table will contain all the deleted DOCID entries. Whenever, we delete a text record (which was indexed), the $N table will be populated with the record's DOCID, which will be later used for index cleanup operation.
---//
---// $N contains delete DOCIDs //---
---//
SQL> desc DR$BLOG_DOC_TXT_IDX$N
Name Null? Type
----------------------------------- -------- ------------------------
NLT_DOCID NOT NULL NUMBER(38)
NLT_MARK NOT NULL CHAR(1)
Let's populate the table with a record and observe its impact on the internal text tables.
---//
---// populate the table with a record //---
---//
SQL> insert into blog_docs (doc_id,doc_title,doc_author,doc_data)
2 values (1,'Sample document','Abu Fazal Md Abbas','This is a sample document.');
1 row created.
SQL> commit;
Commit complete.
Let's validate the content of these text index tables by querying the $I table.
---//
---// no tokens are indexed //---
---//
SQL> select * from DR$BLOG_DOC_TXT_IDX$I;
no rows selected
We could see no tokens are indexed yet. This is because in case of a text indexes, index updates are done asynchronously and we have a CONTEXT index defined on the table column which needs to be synced using the CTX_DDL.SYNC_INDEX procedure after any DML operation unless we configured the index to sync on COMMIT. We can validate that the index is not configured for AUTO SYNC by querying the CTXSYS.CTX_INDEXES view as shown below.
---//
---// text index is not configured for auto sync //---
---//
SQL> select IDX_OWNER,IDX_NAME,IDX_STATUS,IDX_TYPE,IDX_SYNC_TYPE,IDX_SYNC_INTERVAL
2 from ctxsys.ctx_indexes where IDX_NAME='BLOG_DOC_TXT_IDX';
IDX_OWNER IDX_NAME IDX_STATUS IDX_TYP IDX_SYNC_TYPE IDX_SYNC_INTERVAL
--------------- ------------------------------ ------------ ------- -------------------- --------------------
MYAPP BLOG_DOC_TXT_IDX INDEXED CONTEXT
Let's sync the text index and validate if the tokens from the table records are indexed or not.
---//
---// syncing text index with the base table //---
---//
SQL> exec ctx_ddl.sync_index('BLOG_DOC_TXT_IDX');
PL/SQL procedure successfully completed.
NOTE: We have the option of syncing a text index manually or on interval basis or on every commit.
Now, if we query the $I table (DR$BLOG_DOC_TXT_IDX$I), we could see it has all the tokens (TOKEN_TEXT) which are indexed within the document along with the information (TOKEN_INFO) about the ROW and WORD positions in the document where these tokens appear.
---//
---// list of indexed tokens and token info //---
---//
SQL> select * from DR$BLOG_DOC_TXT_IDX$I;
TOKEN_TEXT TOKEN_TYPE TOKEN_FIRST TOKEN_LAST TOKEN_COUNT TOKEN_INFO
--------------- ---------- ----------- ---------- ----------- --------------------
A 0 1 1 1 008803
DOCUMENT 0 1 1 1 008805
IS 0 1 1 1 008802
SAMPLE 0 1 1 1 008804
THIS 0 1 1 1 008801
Each record from the table (being indexed) is assigned a unique DOCID and since, we have populated a single document into the table, we could see there is a single entry with DOCID=1 in the $K table mapping the DOCID with the records physical ROWID as shown below.
---// ---// mapping between DOCID and ROWID //--- ---// SQL> select * from DR$BLOG_DOC_TXT_IDX$K; DOCID TEXTKEY ---------- ------------------ 1 AAAVY/AAbAAAMyFAAA ---// ---// TEXTKEY is the physical ROWID of the record //--- ---// SQL> select rowid from blog_docs; ROWID ------------------ AAAVatAAbAAAMyFAAA
Details in the $R table are stored in internal format in the DATA field containing the ROWIDs for all the DOCIDs which are used for opposite lookup from $K table. This table has just a single record which contains the ROWIDs (in internal format) for the all the DOCIDs in the table.
---//
---// ROWIDs in internal format for all the DOCID //---
---//
SQL> select * from DR$BLOG_DOC_TXT_IDX$R;
ROW_NO DATA
---------- ----------------------------------------
0 00001563F0006C00003321404141
We do not have any entries in $N table, as we haven't yet deleted any indexed records.
---//
---// no deleted DOCID exists //---
---//
SQL> select * from DR$BLOG_DOC_TXT_IDX$N;
no rows selected
Let's perform a quick query against the table and validate if the text index is used or not. For a text search query we can use the CONTAINS operator as shown in the following example. In the example, I am trying to search for documents which contains the word "sample" in it's contents.
---//
---// performing text search //---
---//
SQL> select doc_author,doc_data from blog_docs where contains(doc_data,'sample') > 0;
DOC_AUTHOR DOC_DATA
------------------------- ------------------------------
Abu Fazal Md Abbas This is a sample document.
---//
---// execution plan of the text search query //---
---//
Plan hash value: 145656609
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 7 |
| 1 | TABLE ACCESS BY INDEX ROWID| BLOG_DOCS | 1 | 1 | 1 |00:00:00.01 | 7 |
|* 2 | DOMAIN INDEX | BLOG_DOC_TXT_IDX | 1 | | 1 |00:00:00.01 | 6 |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CTXSYS"."CONTAINS"("DOC_DATA",'sample')>0)
As we could see, when we perform text search using search operators (like CONTAINS), Oracle makes use of the text index (Domain Index) to efficiently find out all the records which matches the search pattern.
Note: Oracle Text provides a rich set of query operators for efficient text search. For a complete list please refer here
Conclusion
In this article, we have discussed about the architecture of a Oracle Text Index. We have explored how the Oracle text engine creates a text index and what all database objects collectively constitutes a text index. In the upcoming article, we will discuss about few of the new features that are introduced in Oracle 12c to improvise the text index processing.
Start the discussion at forums.toadworld.com