One of the most important steps in any machine learning project is the gathering, preparation, and cleaning of the data. Data is the backbone to your project and by spending the time and resources on this initial step you'll be better positioned for success.
There are many times when the data ends up being the most critical piece of a project, even outweighing your choice of algorithm as seen below.
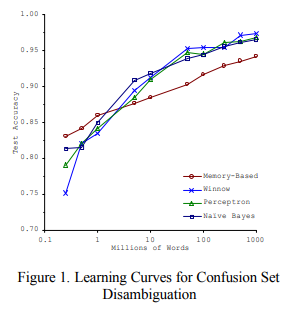
The figure comes from the research paper Scaling to Very Very Large Corpora for Natural Language Disambiguation published by Michele Banko and Eric Brill, which demonstrates different algorithms and their accuracy as the amount of data increases.
In nearly all cases, as the size of the data increases the test accuracy starts to converge. This is an interesting observation in that the more data that is provided the less advanced your algorithm needs to be to provide comparable results.
This could influence your decision on spending more time collecting data rather than improving your algorithm. Let's go over some of the steps required to create a quality data set.
Collecting raw data
Data collection doesn't always get the attention that it deserves, but it's the first step to ensuring you have a performant algorithm. A general rule of thumb is that a simple model on a large data set will perform better than a more advanced model on a small data set.
Data set sizes vary wildly depending on your application and you might have a project requiring anywhere from a few hundred to a few billion examples. A simple reminder though is that the more quality data that you have, the better your model will perform.
Formatting data
"Garbage in, garbage out" describes that nonsensical data coming into your project will result in nonsensical data coming out. Depending on where your data is coming from it might need additional formatting and standardizing. A great, large data set can be rendered powerless with incorrectly formatted data. This is particularly of interest when you're aggregating data from multiple sources.
As an example, let's think about two data sets that relate to houses. One set of data might include a single column with a home buyer's name while another may include individual columns for their first and last names. Each set contains correct and valuable data but your algorithm won't be able to work with it in that state.
Other scenarios might include the feature data itself being formatted differently; phones numbers including spaces versus hyphens or two addresses being formatted differently. These are all examples that need to be taken into account to improve the quality and reliability of your data set.
Quality data
Having a formatted data set is a requirement to having a successful model, but the quality of that data is essential. This isn't always easy to recognize and may require several iterations before you're confident in the resulting data.
In many cases the labeled data set was labeled by a human and may contain errors. Someone may forget to add a digit when labeling a house's price or duplicate a home's listing. Feature outliers are another potential loss of quality. These can be very situational and depending on your needs, a threshold for removal may vary.
Again, using the example of housing, suppose there are a thousand homes in a data set all ranging in price from $200 to $400 thousand dollars and there are three houses worth over one million dollars. Should these outliers be included in your data set? The answer is, it depends. Choose the data set that gives the best results for the problem that you're attempting to solve.
Splitting data
Now that our data is properly formatted, we've ensured the quality, and we have all our relevant features we're ready to split the data. This is done so that we have two sets of data to work with.
One set is for training our model while the other is for testing. The standard for splitting data isn't a direct 50 / 50 split but rather an 80 / 20 split where 80% is used to train your model while 20% is used for testing and evaluation.
Now that you know what percentage of your data should fit into each category, how do you know which data goes where? A good starting place is usually by splitting the data randomly. This doesn't work well for all situations though and often requires additional changes based on your situation.
Learn more about data preparation
This has been a brief overview of preparing data for creating great machine learning models. There are many suggestions and places to start, but as you've probably noticed, the details may change with each project.
Having a quality data set is an essential first step to ensuring your machine learning project runs smoothly.
What tools do you use to prepare and work with your data? Quest Software offers many solutions to help you experience higher productivity, better collaboration and enhanced efficiency. Learn more about how our different products can help with that initial step of data preparation and help you complete your data preparation tasks up to 50% faster.
Questions
If you have any questions about this topic, click "Start Discussion" below, and this topic will go to our Forums Blog Posts page.
Start the discussion at forums.toadworld.com