Although I think that R is the language for Data Scientists, I still prefer Python to work with data. In this blog post, I will show you how easy to import data from CSV, JSON and Excel files using Pandas libary. Pandas is a Python package designed for doing practical, real world data analysis.
Here is the content of the sample CSV file (test.csv):
name,email
"gokhan","gokhan@gmail.com"
"mike","mike@gmail.com"
Here is the content of the sample JSON file (test.json):
{ "customers": [ {
"name": "gokhan",
"email": "gokhan@gmail.com" },
{
"name": "mike",
"email": "mike@gmail.com"
}]
}
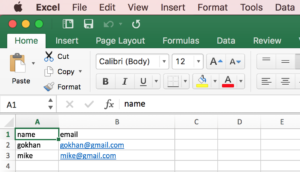
I also created an Excel file (test.xls):
Here is the script which reads each sample file and prints its content:
import pandas as pd
df_json = pd.read_json('test.json' )
print df_json
df_csv = pd.read_csv('test.csv')
print df_csv
df_xls = pd.read_excel('test.xlsx')
print df_xls
When we run the above code, we get the following output:
customers
0 {u'name': u'gokhan', u'email': u'gokhan@gmail....
1 {u'name': u'mike', u'email': u'mike@gmail.com'}
name email
0 gokhan gokhan@gmail.com
1 mike mike@gmail.com
name email
0 gokhan gokhan@gmail.com
1 mike mike@gmail.com
As you can see, all I need is to import panda package and call the related function. The pandas package provides powerful functions that can be used to import the data from these files into “DataFrames” (two-dimensional arrays/matrices).
To be able to read Excel files, you may need to install an additional package to your system. If you get an error while reading excel saying xlrd is missing, run the following code to install the package:
pip install xlrd
One of the important point is, JSON data needs some extra methods to convert it a dataframe because of its schema-less structure. When we import JSON data using Panda, all values (name, email in our sample) are stored in one column. To be able to effectively analyse the data, we need to split this column.
import pandas as pd
df_json_raw = pd.read_json('test.json')
df_json = df_json_raw.apply( lambda x: pd.Series([x[0]['name'],x[0]['email']]), axis = 1 )
df_json.columns=['name','email']
print df_json
name email
0 gokhan gokhan@gmail.com
1 mike mike@gmail.com
I didn’t want to use loops to split the data, so I did a little trick and applied a simple function to transform the customer column. I get “name” and “email”, and then return them as a Panda Series, so our customer column is transformed to two columns (name and email).
As you can see, Panda is a great library to handle different file formats. I’ll continue writing about Python for Data Science series, share more samples about Pandas. See you on next blog post!
Start the discussion at forums.toadworld.com