Hi,
This article will discuss some timings from last month’s FORALL load times. I had a student from a class share his timings using newer syntax that he learned in my class. I will talk about some serious performance considerations that I feel will greatly help your overall application performance. Then, I’ll wrap up the collections conversation with when to use which kind and why. I’ll start with a cool technique I learned from Steven Feuerstein on how to automatically get some additional useful information on row processing error conditions.
Additional Error Information
Last month, I illustrated two ways of processing FORALL errors…with a collection and a newer technique using a table created by a procedure. This procedure creates an ERR$ tagged to the front of the table (click here to review this article).
It might be nice to see the logged-in user who created the error, when the error occurred, and maybe the PL/SQL call stack to show how the code (with line numbers!) got to this PL/SQL routine. Maybe I can discuss this call stack in the future…keep reading my blogs [:)]
It is OK to alter the ERR$ table and add additional columns and a trigger to maintain these additional columns.
ALTER TABLE ERR$_EMP ADD created_by VARCHAR2(30),
created_on DATE,
call_stack VARCHAR2(4000);
CREATE OR REPLACE TRIGGER ERR$_EMP_TRG
BEFORE INSERT OR UPDATE ON ERR$_EMP
FOR EACH ROW
BEGIN
:NEW.created_by := USER;
:NEW.created_on := SYSDATE;
:NEW.call_stack := SUBSTR (dbms_utility.Format_call_stack (), 1, 4000);
END;
Notice that I added a column called ‘created_by’ and used this trigger to plug in the user running this routine, I added a column ‘created_on’ and plugged in the current time stamp, and I added a column called ‘call_stack’ and ran the FORMAT_CALL_STACK routine, putting this information into this column. If it’s a deep call stack, I truncated it to 4000 positions, the length of my column. IF you are expecting a deep call tree, you might have to change this to a LONG or preferably a CLOB column type. Oracle is trying to get away from LONG data types and there are good reasons to do so.
Collection Timings
Brian Gibbs returned to his job after attending my Advanced PL/SQL Tips and Techniques class. He used the technology learned and ran some timings for me against a table with 1.2 million rows.

FORALL Syntax processing an UPDATE statement
This illustration is two comparisons: He compares the FORALL update with all three collection types, and he uses the Oracle10 newer syntax ‘INDICES OF’ that is supposed to help Associative Arrays with processing.
Notice two things in the above timings. First: the ‘INDICES OF’ syntax does indeed help the Associative Array, and second: Associative Arrays do process slightly faster than the other two array types.

FORALL Syntax processing an INSERT statement
This illustration shows INSERT performance against the same 1.2 million rows.
Again, the Associative Array wins the race but there is not a lot of difference between using the ‘INDICES OF’ syntax or not.
So, if you are using FORALL against
Associative Arrays, make sure you are using the ‘INDICES OF’ syntax.
Using Collections for Reference Tables
I do a lot of SQL performance tuning. I see SQL with 6 to 10 reference tables being joined in. The Oracle RDBMS would have a far easier time on the hard parse if there were only a few joins. This can easily be attained if your lookups are using PL/SQL.
I would put these at the package header level so that ANY PL/SQL running in your application can access the Associative Table with the look up information.
Useful information would be the names of the 50 United States, all the country names, county names, city names, part descriptions, etc. Anything where you are storing a code and looking up character descriptions in another table, requiring a join on your SQL.
Sure, it is easier to just code the SQL but if you can cut down on all these joins, your SQL will perform much faster AND you are not repeatedly looking up the same information from within your PL/SQL routines.
Once these Associative Arrays are loaded, access to the data/descriptions is memory speed (i.e., extremely fast).

Package Level Associative Array
This array is in the SPEC line…it will be visible to your entire application. IF this array was just for use inside the package, I would have put it in the package body.

Associative Array Load Code
Notice the lone BEGIN at the end of the package. This section can be used for a variety of uses and is run once when the package is initially executed. Notice I’m loading the Associative Array using the highlighted syntax. Loading the array using a loop guarantees DEPTNO of 10 goes into the 10th slot of the array, DEPTNO 20 goes into the 20th slot, etc. This works equally well for character data too.
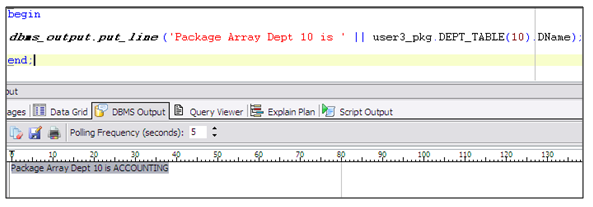
Accessing Associative Array
This illustration shows the syntax used to do a direct access of the Associative Array using the same lookup code that you would have used in your SQL statement WHERE clause. The other two collection types would need looping syntax but this one looks up the exact position based on your data from a variable using similar syntax.
Best Practices for Collections
I’ll discuss best practices for each of the collection types.

When to use Associative Arrays
I generally use Associative Arrays unless I am doing massive row processing, then I’ll switch over to the VARRAY because of its LIMIT clause and ease of sizing the space required for the collection. I discuss this in my class.
I generally find Associative Arrays arrays sufficient to meet my needs of storing reference information for the related routines.

When to use Nested Tables
Nested Tables are good for collecting rows, changing the information, then posting the rows back to Oracle. This collection is good when the number of elements is not known at create time, or the number of elements can vary. This collection allows for easy interaction with SQL when stored at the database level although the order of the elements is not maintained.
**Caution** – When using collections in this manner, there will be NO row level locking. Unless your process issues a lock on the object with a lot of changes, there is a risk that your changes could step on another process’s changes!

When to use Varrays
This collection type is useful when the number of elements is fixed or known in advance. This is a good collection type when working with arrays from other languages. When this collection is stored at the database (in a column) the order of the elements is maintained.
Again, be careful with DML operations, as there is no row-level locking.

Newer Syntax for Collections
Another feature implemented with Oracle10g is that a collection can be part of the data type used to define a collection. Nested Tables and Varrays can have nested collections, also called multi-dimensional collections.
Summary
I’ve completed the discussion of collections, showing some useful timing using newer Oracle syntax. I illustrated a clever way of collecting more information on error conditions, and I illustrated a serious performance gain that can be realized, if this technique is implemented and your apps do a lot of reference data lookup.
The next article in the PL/SQL series will relate to dynamic SQL. This is a related topic to the collections we just covered and I’ve used some of this kind of SQL to solve partitioned-SQL performance issues!
I hope you find these tips useful in your day to day use of the Oracle RDBMS.
Dan Hotka
Author/Instructor/Oracle Expert
Start the discussion at forums.toadworld.com