In some earlier tutorials we introduced Kubernetes cluster manager and discussed using it with MySQL database, Oracle Database, and Oracle NoSQL Database. Kubernetes cluster manager orchestrates a cluster of Docker containers, providing replication, auto scaling, rolling updates, service abstraction, high availability, and load balancing. In this tutorial we shall discuss using PostgreSQL with Kubernetes.
How Does Kubernetes Improve Performance?
Kubernetes makes feasible a microservices architecture which has several benefits as compared to the monolithic architecture. Kubernetes is suitable for developing scalable, reliable database services. A Pod is a set of one or more containers, each of which is running an application (such as a database), which could be same or different across a Pod. A service is an abstraction over a set of Pods for clients to be able to invoke a Pod application.
Earlier versions of Docker did not provide any native cluster management features. But Docker Engine 1.12 integrates the Docker Swarm cluster manager. Docker Swarm does overcome some of the earlier limitations of Docker by providing replication, load balancing, fault tolerance, and service discovery, but Kubernetes provides some features suitable for developing object-oriented applications. A Pod abstraction is the atomic unit of deployment in Kubernetes. A Pod may consist of one or more containers. Co-locating containers has several benefits as Docker containers in a Pod share the same networking and file system and run on the same node, which reduces the network latency between the containers. Docker Swarm does not support auto scaling directly. While Docker Swarm is Docker native, Kubernetes is more production ready, having been used in production at Google for more than 15 years.
How Does Kubernetes Improve Collaboration?
Pods at the backend of a Kubernetes service collaborate to serve client requests. Client traffic to a Kubernetes service is routed to one of the Pods with round robin load balancing which is transparent to the client accessing a service. A service is loosely coupled with the Pods it represent, which makes it easier to modify or update either of the service or the Pods tier. Pods may be added or removed without an interruption of service.
Kubernetes Helm charts provide collaboration among users. With Helm charts resource definitions developed by end users may be shared among other users who might have a similar application requirement. Helm is a package manager for Kubernetes, just as YUM is a package manager for RPM based systems. Helm charts are the packages managed by Helm, similar to the RPM packages. Helm charts are curated, reusable application definitions for Kubernetes Helm.
In this tutorial we shall discuss using PostgreSQL database with Kubernetes. The benefits of Docker container are a lightweight, scalable platform for developing applications and using software in a virtual-machine-like environment, with each Docker container being a snapshot of the underlying OS. A virtual machine, in contrast, packages a whole OS, which could be several GB and not recommended for developing lightweight and scalable applications.
Setting the Environment
In this example, we have used Ubuntu on Amazon EC2 to run a multi-node (2 nodes) Kubernetes cluster.

Two approaches may be taken to running PostgreSQL database on a Kubernetes cluster. One is the declarative approach, in which the database replica and service configuration are provided using YAML configuration files. The second approach is the imperative-style command-line. We shall discuss each of these.
Configuring the Replication Controller and Service Declaratively
Create two YAML files, one for the replication controller definition and the other for the service definition. The postgres-rc.yaml is for a replication controller and the postgres-service.yaml is for the service.

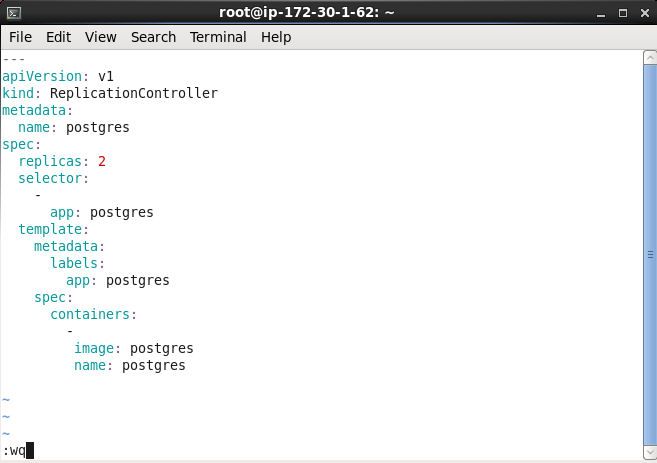
In the postgres-rc.yaml specify two replicas and a Pod spec for the Docker image “postgres”. The Pod template metadata includes a label “app: postgres”, which translates to app=postgres. The postgres-rc.yaml is listed:
---
apiVersion: v1
kind: ReplicationController
metadata:
name: postgres
spec:
replicas: 2
template:
metadata:
labels:
app: postgres
spec:
containers:
-
image: postgres
name: postgres
Validate the YAML syntax using some YAML validator such http://www.yamllint.com/ as improper spacing could result in a syntax error. To validate the schema conformance of the replication controller definition file the schema is available at http://kubernetes.io/docs/api-reference/v1/definitions/#_v1_replicationcontroller. The RC YAML file is shown in a vi.
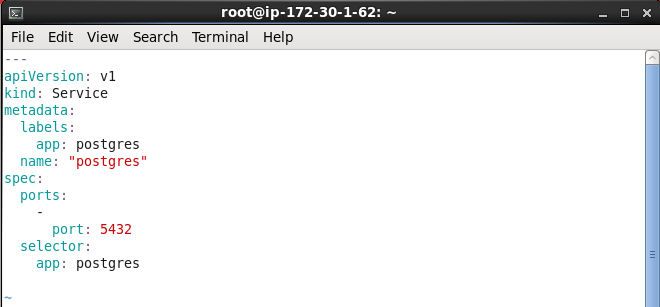
The postgres-service.yaml file defines a Service. The selector expression should be the same as a Pod template label in the replication controller for the service to route traffic to the Pods. The spec label is set to “app: postgres”, which translates into app=postgres, and is the same as the Pod template label in the postgres-rc.yaml file.
---
apiVersion: v1
kind: Service
metadata:
labels:
app: postgres
name: “postgres”
spec:
ports:
-
port: 5432
selector:
app: postgres
Validate the YAML file. The YAML validator only validates the syntax and not the schema conformance. The Service schema is available at http://kubernetes.io/docs/api-reference/v1/definitions/#_v1_service. The service YAML file is shown in a vi.
Creating a PostgreSQL Service Declaratively
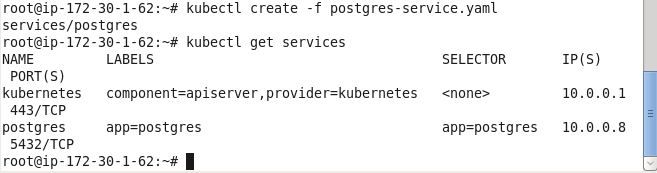
To create the Kubernetes service from the service definition file, run the following kubectl create command.
kubectl create -f postgres-service.yaml
Subsequently list the services.
kubectl get services
As the output indicates, a service called “postgres” gets created and listed.
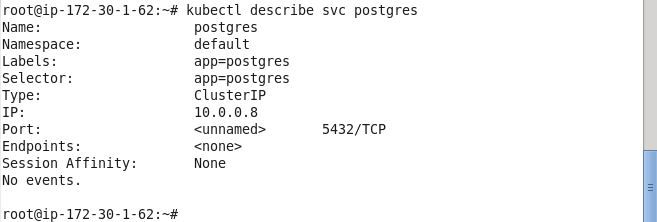
Describe the service.
kubectl describe svc postgres
The service description lists the service name, namespace, labels, selector, and IP. No service endpoints are initially listed, as Pods have not been created yet.
Creating a PostgreSQL Replication Controller Declaratively
Having created a service, next we shall create a replication controller. Run the following kubectl create command to create a replication controller from the postgres-rc.yaml file.
kubectl create -f postgres-rc.yaml
A replication controller called “postgres” gets created.

Subsequently list the replication controllers.
kubectl get rc
And describe the rc.
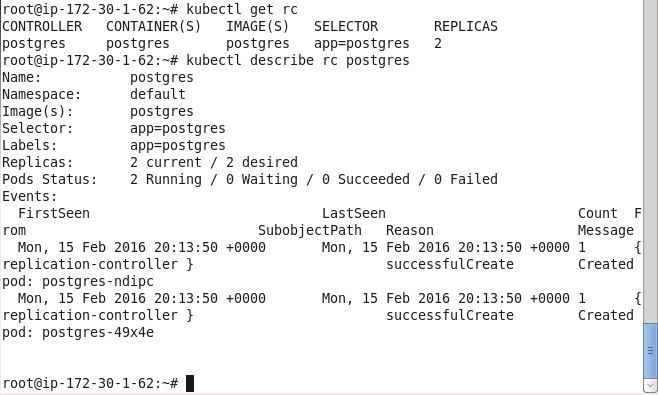
kubectl describe rc postgres
The “postgres” rc gets listed. The rc description indicates that 2 replicas are running.
List the pods.
kubectl get pods
Two Pods get listed as running and ready.

When we first listed the service description no service endpoints were listed. List the svc again.
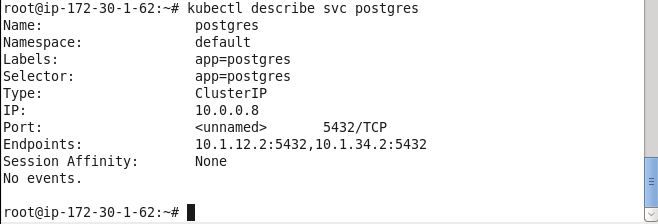
kubectl describe rc postgres
Two service endpoints corresponding to the two Pods get listed. The service endpoints route traffic to Pods.
Creating a PostgreSQL Database Table
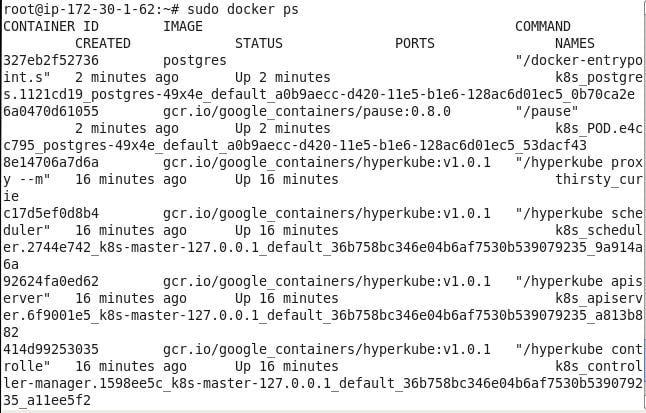
In this section we shall create a database table. Two alternatives are available to start an interactive shell. One is to use the kubectl exec command to start a tty for a pod. The second is to use the docker exec command with a Docker container; this alternative is what we shall use. List the Docker containers with docker ps.
Obtain the container id for one of the Docker containers for the postgres Docker image and use the docker exec command to start a bash shell.
sudo docker exec -it <container id> bash
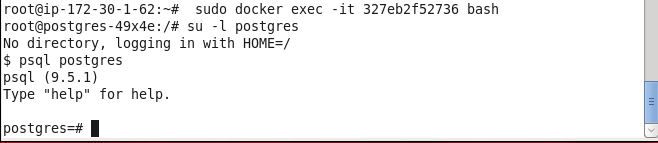
A bash shell gets started to connect to a Pod. Start a login shell for PostgreSQL database “postgres”.
su –l postgres
Start the PostgreSQL client terminal.
psql postgres
The postgres=# command prompt should get displayed.
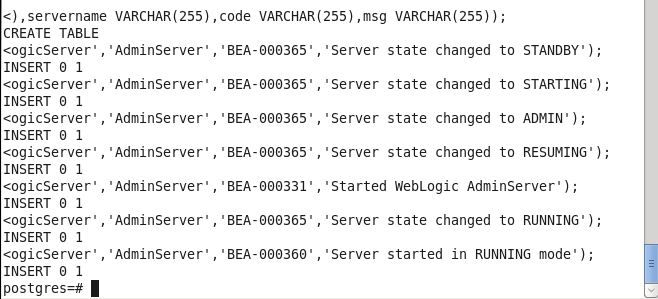
Run SQL script to create a database table called wlslog and add data to the database.
CREATE TABLE wlslog(time_stamp VARCHAR(255) PRIMARY KEY,category VARCHAR(255),type VARCHAR(255),
servername VARCHAR(255),code VARCHAR(255),msg VARCHAR(255));
INSERT INTO wlslog VALUES('Apr-8-2014-7:06:16-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state changed to STANDBY');
INSERT INTO wlslog VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state changed to STARTING');
INSERT INTO wlslog VALUES('Apr-8-2014-7:06:22-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000360','Server started in RUNNING mode');
A database table gets created.
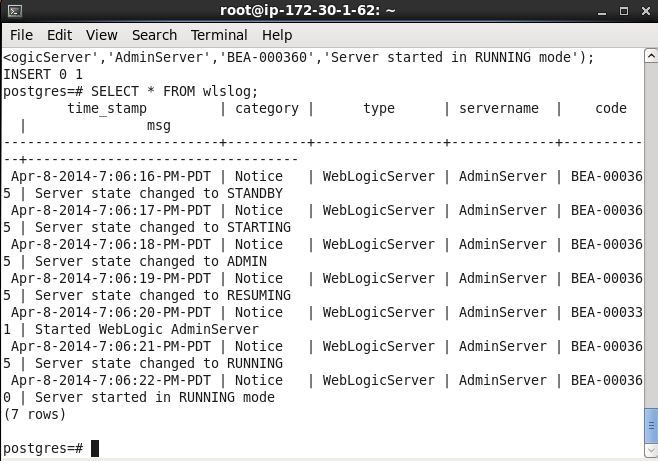
Subsequently select data from the database table.
SELECT * FROM wlslog;
The table data gets listed.
Quit the PostgreSQL client terminal and exit the bash shell.

Scaling the Pod Cluster
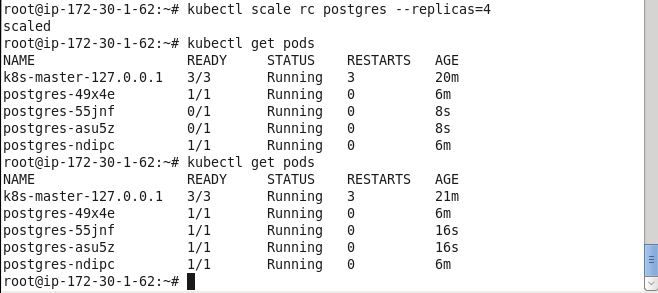
The Pod cluster may be scaled to increase/decrease the number of replicas. As an example, increase the replicas from 2 to 4 with the kubectl scalecommand.
kubectl scale rc postgres --replicas=4
Subsequently list the Pods.
kubectl get pods
Initially some of the Pods may not be ready and/or running. Run the preceding command again after a few seconds and all the Pods should be running.
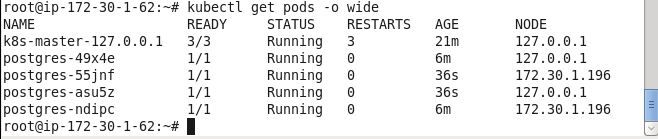
The nodes the Pods run on may also be listed.
kubectl get pods -o wide
The nodes for the Pods also get listed.
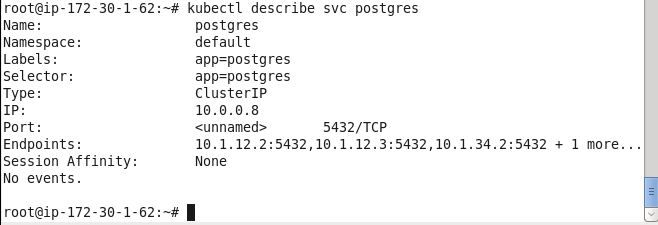
Describe the service postgres again.
kubectl describe svc postgres
The service endpoints should have increase to four.
Deleting the Replication Controller
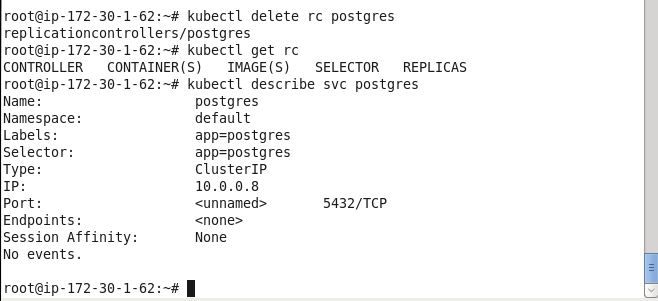
Delete the replication controller with the kubectl delete command.
kubectl delete rc postgres
Subsequently list the replication controllers.
kubectl get rc
Also describe the service.
kubectl describe svc postgres
The rc gets deleted and does not get listed subsequently. The svc does not list any service endpoints.
Stopping the Service
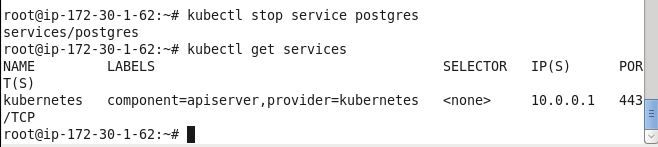
Stop the service “postgres” and subsequently list the services.
kubectl stop service postgres
kubectl get services
The service gets stopped and does not get listed subsequently.
Creating a Replication Controller and Service Imperatively
Next, we shall discuss creating a PostgreSQL database Pod cluster imperatively without configuration files. Create a replication controller called “postgres” from Docker image “postgres” with 2 replicas and port as 5432.
kubectl run postgres --image=postgres --replicas=2 --port=5432
An rc gets created.

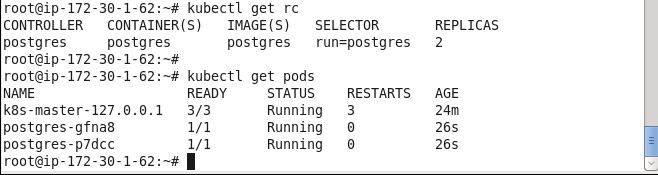
Subsequently list the replication controllers.
kubectl get rc
Also list the Pods.
kubectl get pods
Two Pods get listed.
Next, expose the rc as a service of type LoadBalancer on port 5432.
kubectl expose rc postgres --port=5432 --type=LoadBalancer
Subsequently list the services.
kubectl get services
A “postgres” service gets created and listed.
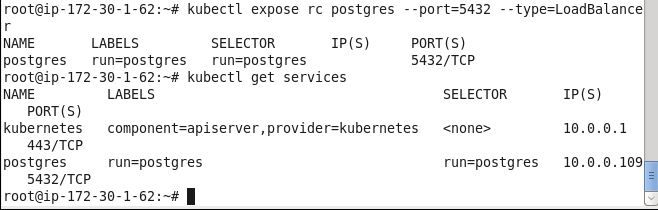
Describe the service to list two service endpoints.
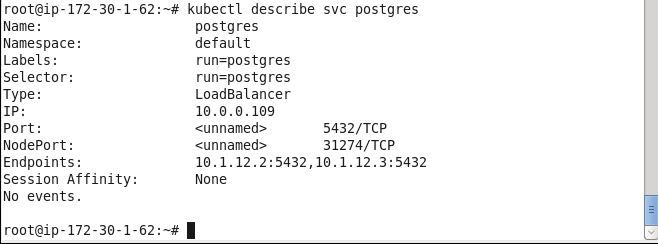
Subsequently, a database table may be created in a PostgreSQL client terminal as discussed in the preceding sections.
Listing the Database Logs
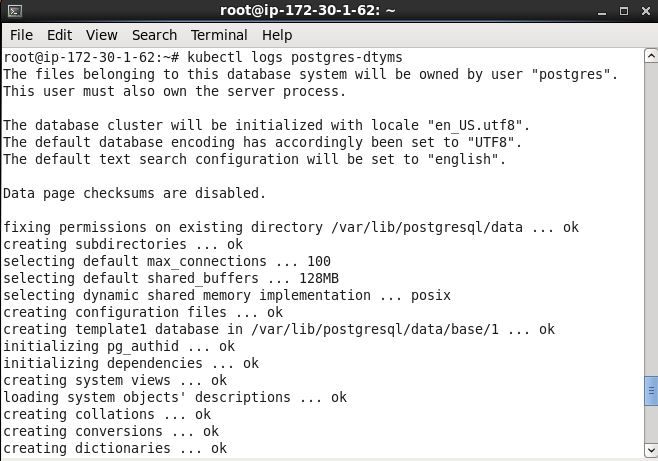
The logs for a Pod may be listed with the kubectl logs command.
kubectl logs postgres-dtyms
The output from the command should show the database getting initialized.
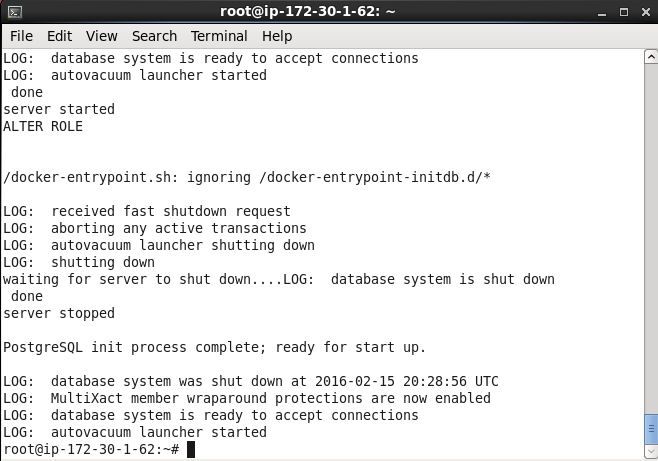
If the database was also shut down the logs include the database shutdown.
In this tutorial we discussed using PostgreSQL database with Kubernetes. Kubernetes microservices architecture provides performance benefits to develop a scalable and reliable database service. Kubernetes also provides collaboration features such as multiple Pods collaborating to serve client requests and Helm charts for collaboration on Kubernetes resources.
Start the discussion at forums.toadworld.com