Hay una expresión del mundo del Big Data que vengo escuchando cada vez con más frecuencia. Me refiero al término “dataprep”. En Big Data, la palabra “dataprep” alude a la “preparación de datos” e incluye todas las actividades relacionadas con la recopilación, combinación y organización de datos desordenados, inconsistentes y no estandarizados provenientes de fuentes diversas. En prácticamente todo proyecto de Big Data nos encontraremos ante la necesidad de validar, limpiar y transformar los datos que recibimos. Una vez que hayamos finalizado con todas estas tareas de “preparación de datos” habremos logrado estructurarlos y estaremos en condiciones de analizarlos con herramientas de inteligencia de negocio.
Aquellos que hemos trabajado previamente en proyectos de Datawarehousing muy probablemente nos formulemos la siguiente pregunta: no es entonces dataprep sinónimo de ETL? Hagamos un poco de memoria. Con ETL nos referimos a “Extracción, Transformación y Carga”. En un Datawarehouse “extraemos” datos de distintos sistemas que pueden ser homogéneos o heterogéneos. Luego los datos son “transformados” a un formato y estructura adecuados para su análisis. Por último los datos transformados son “cargados” o almacenados en un nuevo espacio a fin de poder ser analizados o explotados por herramientas de inteligencia de negocio.
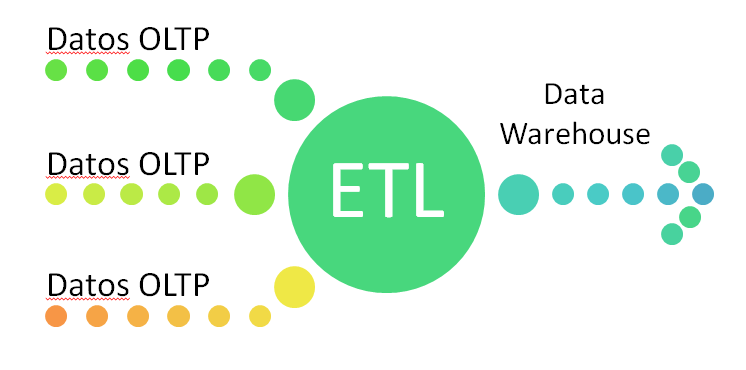
Esquema de procesamiento de un Datawarehouse tradicional
Entonces, cuál es la diferencia entre dataprep y ETL? Quizá la necesidad de un nuevo término responda a los nuevos requerimientos planteados por algunas de las famosas “V” de la era del Big Data:
- Volúmen. El volumen de datos que manejamos en los proyectos de Big Data es muy superior a lo que estábamos acostumbrados en un Datawarehouse tradicional. Para poder procesar el enorme flujo de datos que recibimos necesitamos contar con técnicas y herramientas de procesamiento en paralelo altamente escalables.
- Variedad. Si bien en un Datawarehouse tradicional recibimos datos de sistemas heterogéneos, la realidad indica que en la gran mayoría de los casos colectamos datos residentes en bases de datos transaccionales de tipo relacional. En los proyectos de datos de Big Data los datos provienen de fuentes diversas que pueden ir desde teléfonos inteligentes hasta datos generados por máquinas y/o sensores.
- Velocidad. Tanto la velocidad con que se generan los datos como la rapidez con que se necesita tomar decisiones analíticas obliga a una transición que pasa del procesamiento en lotes tradicional hacia un tipo de procesamiento en casi tiempo real.
Como te contaba al principio de este artículo, dataprep es un término que vengo escuchando cada vez con más frecuencia. A qué se debe? Parece ser que muchos de los proyectos de Big Data están sufriendo un problema común a casi todos ellos. La mayor parte del tiempo de los proyectos de Big Data se va en las actividades de preparación de datos, reduciendo de este modo, el tiempo para el análisis. Hay una clara necesidad de reducir el tiempo dedicado a la preparación de datos. Y como consecuencia de esta situación han aparecido y siguen emergiendo compañías que ofrecen productos y herramientas que pretenden disminuir el tiempo dedicado a la preparación de datos. Según algunos especialistas, las llamadas herramientas de “preparación de datos de autoservicio” (self-service data preparation tools) serán las “vedettes” del Big Data en los próximos años. Según analistas de Gartner el mercado de software de preparación de datos de autoservicio llegará a los mil millones de dólares para 2019.

Flujo de procesamiento en Big Data
Cuando nos adentramos en el mundo de estos productos de software nos encontramos con que no sólo pretenden disminuir los tiempos de preparación de datos en los proyectos de Big Data; sino que también aspiran a que las actividades de preparación de datos no queden limitadas al ámbito de TI o de unos pocos ingenieros de datos. Las compañías detrás de estos productos procuran que su software también pueda ser adoptado por usuarios de negocio y que ellos mismos puedan crear conexiones e integraciones de datos.
Te propongo hacer el siguiente ejercicio. Supongamos que tú y yo conformamos un equipo de trabajo en el área de TI de una compañía. La organización ha decidido adquirir una herramienta de preparación de datos y pretende que sea adoptada por usuarios de negocio de sectores diversos dentro de la organización: Recursos Humanos, Contaduría, Finanzas, Auditoría, Marketing, etc. Los usuarios no recibirán “todo hecho”, tendrán que utilizar la herramienta para preparar los datos por sí mismos. Sin embargo, el director nos ha pedido a nosotros que evaluemos productos y recomendemos el que nos parece mejor desde el punto de vista técnico. ¿Qué características evaluarías? Por supuesto que la lista de prestaciones a ponderar será subjetiva. Es poco probable que tu lista coincida con la mía. De ahí lo interesante del ejercicio. A partir de ahora va mi lista, te propongo que luego compartas la tuya:
- Facilidad de uso. Este punto me parece fundamental. Hay que tener en cuenta que el usuario no será un ingeniero de datos o persona con formación en TI. El usuario será un analista de negocio (a este tipo de usuario sin formación en TI se lo suele llamar “Citizen User”). Si la herramienta es difícil de usar, probablemente no sea adoptada y el proyecto fracase. ¿Qué significa que sea fácil de usar? Que tenga una interfaz gráfica, con facilidades del tipo copiar y pegar; que no requiera conocimientos de programación o scripting y que ofrezca wizards que simplifiquen las tareas.
- Obtención rápida de resultados. Si además de extraer y transformar los datos, la herramienta habilita la posibilidad de poder analizar los datos y sacar conclusiones rápidamente, seguramente los usuarios le darán la bienvenida. La posibilidad de crear gráficos y tablas de tipo “Drill Down” de manera sencilla permitirá profundizar sobre los datos y detectar patrones o valores atípicos de manera rápida.
Personalmente, creo que estos dos puntos son los más importantes y que aplican a prácticamente cualquier proyecto. Luego vienen otros elementos a considerar, que incluso podrían variar de acuerdo con las características particulares de cada situación: ¿se requerirá acceso a múltiples fuentes de datos heterogéneas? ¿O es suficiente con dos o tres fuentes de datos específicas? ¿Requeriremos un espacio de trabajo colaborativo?
¿Y tú? ¿Qué cualidades buscarías en una herramienta de preparación de datos?
Nos vemos!
Start the discussion at forums.toadworld.com