There is an expression in the Big Data world that I have been hearing more and more frequently. It is the term "dataprep“. In Big Data, the word “dataprep” means “data preparation” and it refers to all the activities related to the collection, combination, and organization of disordered, inconsistent, and non-standardized data coming from many different sources. In virtually every Big Data project we will find the need to validate, clean, and transform the data we receive. Once we have completed all of these “data preparation” tasks we will be provided with structured data and we will be able to analyze it with business intelligence tools.
Those of us who have previously worked on Data Warehousing projects are most likely to come up with the following question: Isn’t dataprep a synonym of ETL? Let's review some Data Warehousing concepts:
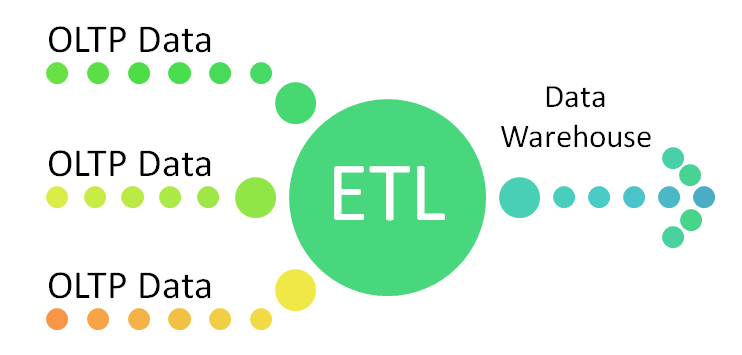
ETL stands for "Extraction, Transformation, and Load". In a Data Warehouse we "extract" data from different systems that can be homogeneous or heterogeneous. Then the data is "transformed" into a structure and format suitable for analysis. Finally the transformed data is "loaded" or stored in new storage so that it can be analyzed or exploited by business intelligence tools.
Traditional Data Warehouse Pipeline
So, what's the difference between dataprep and ETL? Perhaps the need for a new term comes from the new requirements imposed by the famous "V’s" of the Big Data era:
- Volume. The volume of data we handle in Big Data projects is far greater than what we were accustomed to in a traditional data warehouse. In order to process the huge data flow we receive, we need to make use of highly scalable parallel processing techniques and tools.
- Variety. Although in a traditional data warehouse we receive data from heterogeneous systems, in the vast majority of cases we collect data residing in transactional relational databases. In Big Data projects data comes from diverse sources that range from smart phones to machine-generated data from sensors.
- Velocity. Both the speed at which data is generated and the speed at which analytical decisions are made have created the demand fora transition from traditional batch processing to near real-time processing.
As I said at the beginning of this article, dataprep is a term that I have been hearing more and more frequently. The reason? It seems that many Big Data projects are suffering froma common problem. Most of the time spent on Big Data projects goes into data preparation activities, thus reducing the valuable time required for analysis. There is a clear need to reduce the time spent on data preparation. And as a consequence of this situation many companies are starting to offer products and tools that aim to reduce the time spent on data preparation. According to some specialists, the so-called “self-service data preparation” tools will be the hottest software tools of the coming years. According to Gartner analysts, the market for self-service data preparation software will have reached $ 1 billion by 2019.

Big Data pipeline
When we enter the world of these software products, we find that not only do they try to reduce data preparation times in Big Data projects but they also aim to ensure that data preparation activities are not limited to the IT field or to a few data engineers. The companies behind these products ensure that their software can also be adopted by business users who are able to create connections and data integration by themselves.
I propose to do the following exercise. Let's suppose that you and I are part of a team in the IT area of a company. The organization has decided to acquire a data preparation tool that will be adopted by business users from different sectors within the organization: Human Resources, Accounting, Finance, Auditing, Marketing, etc. The users will have to use the tool by themselves to prepare the data. However, the director has asked us to evaluate products and recommend the one that seems best from a technical point of view. What characteristics will you evaluate? Of course the list of features to be weighed will be subjective. Your list is unlikely to be the same as mine. Hence the interesting thing about this exercise. Here’s my list, I propose that you create and share your own:
• Easy to use. This point seems fundamental to me. Keep in mind that the user will not be a data engineer or person with IT training. The user will be a business analyst (this type of user without IT training is usually called a "Citizen User"). If the tool is difficult to use, it probably will not be adopted and the project will fail. What does it mean that it is easy to use? It should have a graphical interface, with copy and paste features; it should not require programming or scripting skills and offers wizards that simplify tasks.
• Fast results. If in addition to extracting and transforming the data, the tool enables the possibility of obtaining insights quickly, surely the users will welcome it. The ability to create graphs or “drill down” tables in a simple way will allow to deepen on the data and detect patterns or outliers very quickly.
Personally, I think these two characteristics are the most important and they apply to practically any project. Then there are other elements to consider, which may vary according to the particular characteristics of each situation: Will it require access to multiple sources of heterogeneous data? Or is it enough with two or three specific data sources? Will we require a collaborative workspace?
And what about you? What qualities would you look for in a data preparation tool?
Let me know.
See you!
Start the discussion at forums.toadworld.com