By Dan Hotka
Hi,
Toad Data Point has been around a while. Its primary use is preparing data and assisting with data analysis. The power of this tool is that it can pull and include data from just about any data store, and mix that data for specific and unique needs.
I’ve never seen a tool that could pull and include columns and data from so many different places. Being part of the Toad family, it has many of the cool features found in the development version of Toad, such as the SQL Editor and Query Builder! You can even reverse your SQL into the Query Builder.
This article is about data preparation, though. Toad Data Point allows for the scrubbing and transformation of data and has some clever visuals to help find any problem data within a given data set. The changes are implemented in a series of rules and do not change the source data but only how the data is being visualized. These rules can be saved so that they can be repeated/included in future data transformations using the same or similar data sets. These rules can also be used as part of an Automation stream where the rules are automatically applied to the result of a SQL perhaps.
Kind of beyond the scope of this article but Toad Intelligence Central, a useful repository for not only Toad things but for your business documents that need to be shared with the group, perhaps…but these data scrubbing and automation scripts can be pushed to this Intelligence Central repository, run there, and the results become visible to anyone (the group perhaps) that has permissions to see and retrieve it.
Log into Toad Data Point. Select your data using Query Builder. I have a special EMP table I use as an example that has a messy EMAIL field.
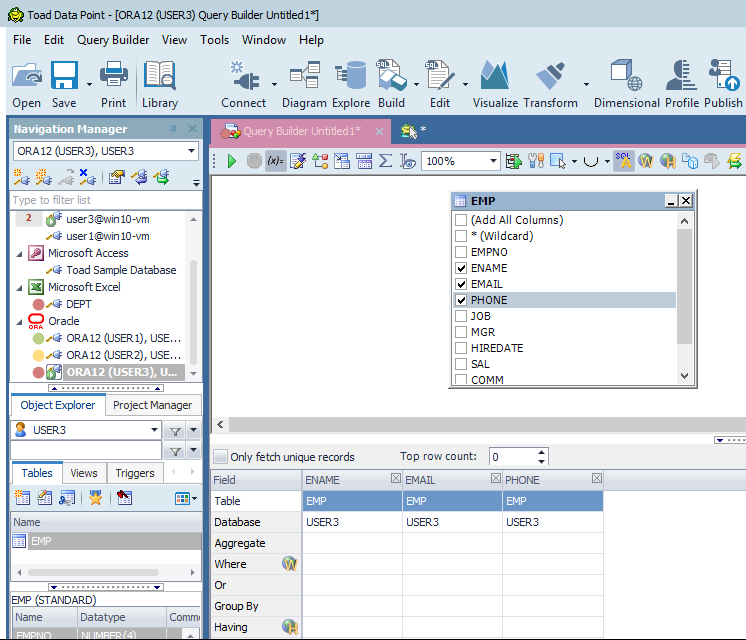
We have our three fields of interest by using a drag-and-drop operation and selecting the fields using just a click of the mouse. Execute the Query (using the green button) and examine the results.
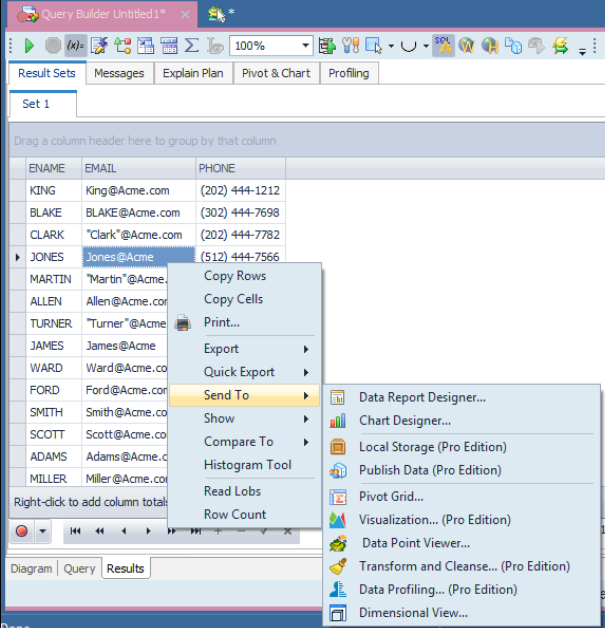
Notice above that we have email addresses that do not have a .com suffix, and some include quotes. Right click selecting ‘Send To’ then ‘Transform and Cleanse…’.
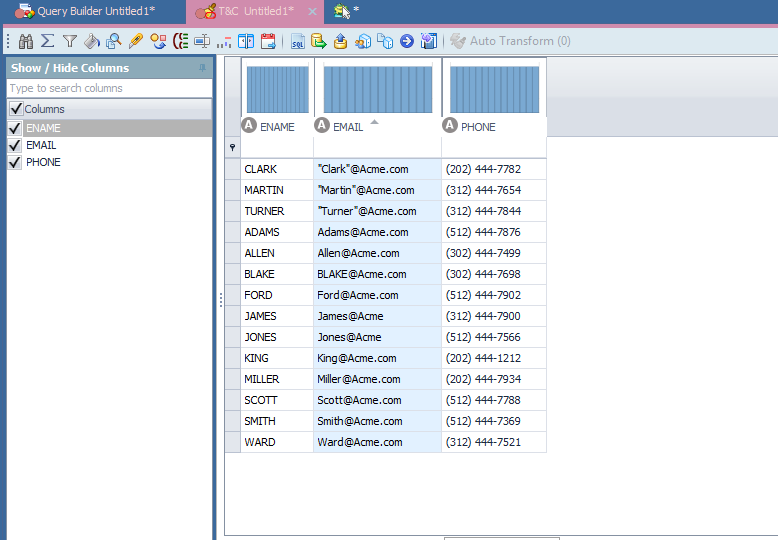
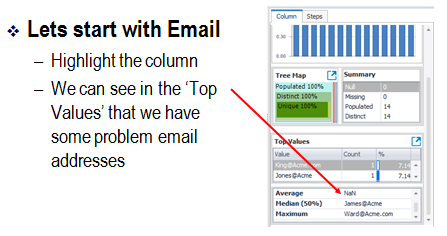
There are some features along the right side to help us find the issues.
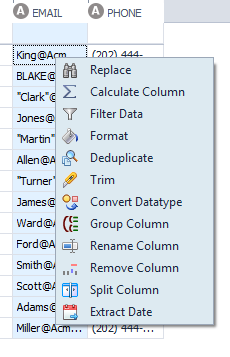
We will use the Replace feature to fix our problems. Notice there are many other things you can do…including Split the column. This feature is useful for, say, phone numbers, to make the area code and the phone number separate columns. You can filter, rename, and add columns (using the Calculate Column selection).
Right Click and select ‘Replace’.
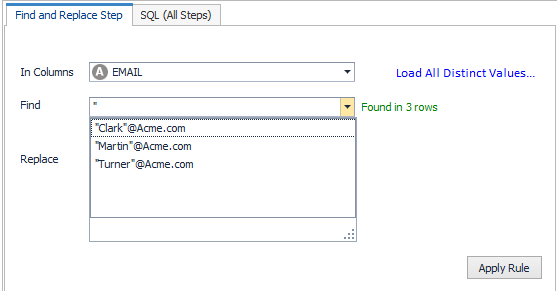
Let’s start with the double quotes. Fill out the grid for the find but leave the replace blank. Click on Apply rule. Notice the rule appears in the ‘Steps’ tab on the right hand side. You can save these, drag them up/down (change the order of the steps), delete them, edit them.
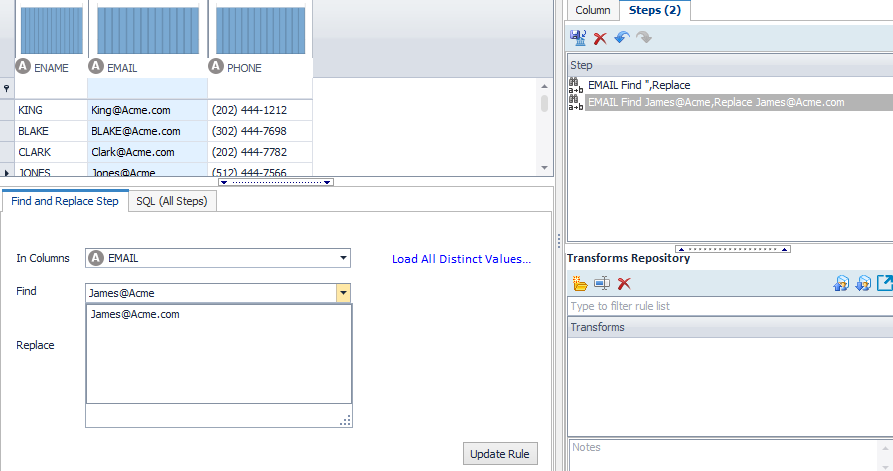
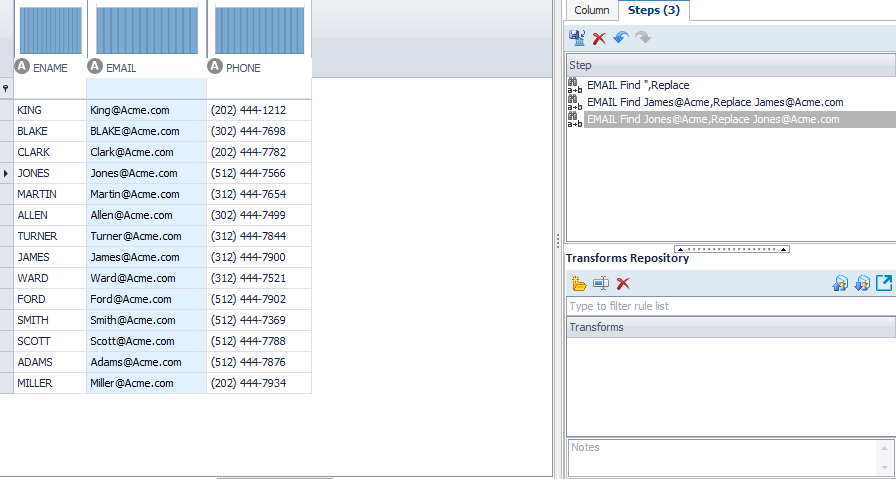
The missing suffix is a bit more messy. If we simply replace all of the above email addresses using the replace, we have to do them one at a time. In the future, what if there are more mistakes?
There are a couple of options here.
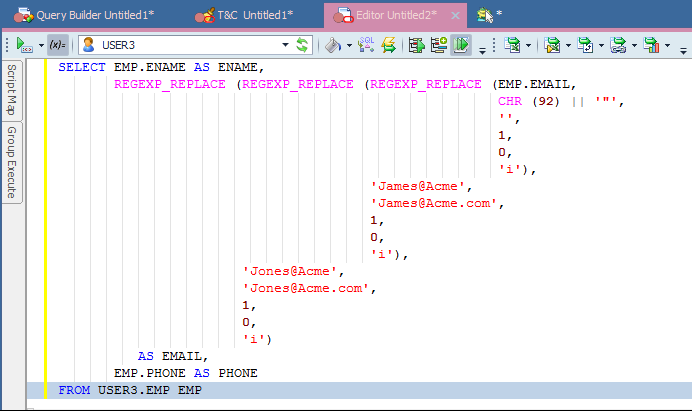
You can click the SQL button along the bottom, transferring the SQL to the Editor where, if you have the knowledge, you can adjust the SQL to fix the issues across the entire data set.
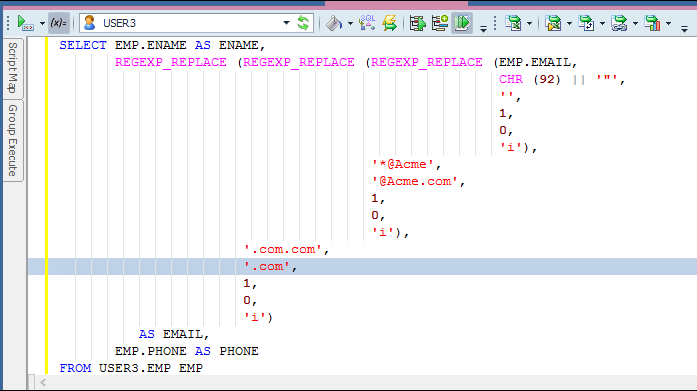
I got this to work in the SQL by making some simple changes to the syntax. But…this type of fix will just fix things for this one data pull; the rules cannot be saved and used for another.
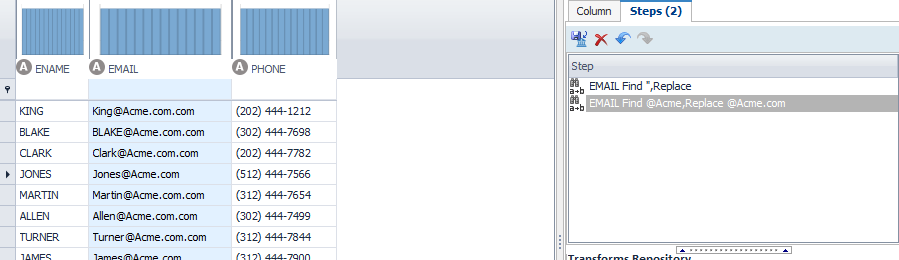
I take the above knowledge and make two rules…one to fix the missing .com; but this fix makes a mess of the addresses that already had a .com…hmmmmm.
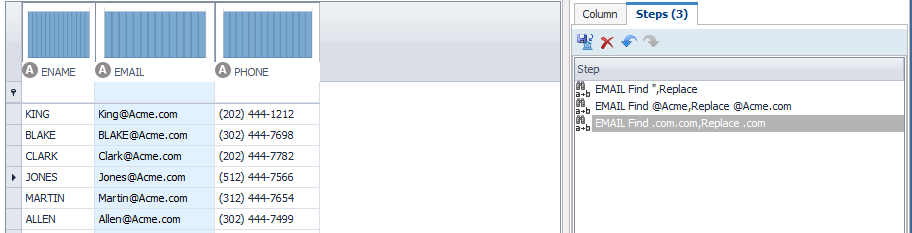
So I add another rule for .com.com back to a single .com. You can drag and drop these rules to be performed in any order. They are performed top down.
Save your rules, give them a name. Next time you need to cleanse an email column, just open this file and it will pick up these rules. You can publish the rules to the repository for others to use, you can include them in Automation…so…that when data is being prepared for use, these rules are automatically applied before the analyst/end user gets the final result. You can then store the final result as a table data (several ways to do this too) so analysts/end users use the cleansed data for their reporting needs, no need for everyone to do the same transformation steps. This can all be set up ahead of time and automated for everyone’s gained productivity.
Start the discussion at forums.toadworld.com