With the increasing scale of data stored by web scale applications, several NoSQL databases have become available. The NoSQL databases are different from the relational databases (such as Oracle database and MySQL) in their data model and scale of data stored. Most web data being unstructured, NOSQL databases are designed to store unstructured data in addition to structured data. DynamoDB became available recently (2012) in comparison to some of the other NoSQL databases such as Apache Cassandra (2008) and MongoDB (2009). Why another NoSQL database, DynamoDB? DynamoDB is a Database-as-a-service (DBaaS) in comparison to the locally running databases such as Apache Cassandra, Couchbase and MongoDB.
What Makes DynamoDB Agile
AWS DynamoDB is a cloud NoSQL database, which implies the database is hosted in the cloud. A developer does not download and install a database on a local machine but instead accesses the database service on the Amazon Web Services (AWS) cloud. A developer does not even have to manage the database after creating it, as DynamoDB is a fully managed database. According to a recent Forrester report DynamoDB is the most commonly used NoSQL cloud database. What features does DynamoDB offer that make it suitable for next generation applications?
– DynamoDB is a fully managed cloud NoSQL database service. Software and hardware provisioning, installation and configuration, scaling, replication, patching, partitioning are all managed.
– AWS Management Console is integrated for creating, updating, deleting, querying, managing and monitoring database and database tables.
– Dynamo DB is built on Solid State Drives (SSDs) for low latency and high throughput
– It offers seamless scalability ranging from a small scale to an unlimited large scale database. There is no limit on the quantity of the data stored or on data throughput (though a request may need to be made to Amazon for throughput exceeding a certain limit)
– It offers single digit millisecond latency not affected by scale
– Flexible data model: key-value or document store
– Schema-free database designed for structured and unstructured data
– Supports both eventually consistent and strongly consistent consistency models
– Highly available and durable with automatic, synchronous data replication across three different zones in a region. Failure of a single AWS Zone does not cause the database to become unavailable.
– Globally distributed applications with cross-region replication of DynamoDB table/s across multiple AWS Regions.
– Automatic partitioning and SSD technologies to support consistent performance at any scale
– Highly scalable within a user-configured request capacity with continuous high throughput. Scales automatically based on requirements.
– Fine grained access control based on AWS IAM
– Suitable for mobile apps, digital ad serving, and web session management, to list some of the applications. Large objects (>10MB) such as binary files and multi-media files may be stored in S3 and metadata stored in DynamoDB.
– Time ordered sequences of item level changes with DynamoDB Streams
– Efficient querying based on secondary indexes
– Integrated with Elasticsearch for full-text search. Integrated with Titan Graph database for storing graphs. Integrated with Elastic Map Reduce (Amazon EMR) for data analytics. Integrated with AWS DataPipeline to process and move data across different AWS compute and storage services.
– Accessible via Restful HTTP API from applications running in any OS
– For those starting with DynamoDB a downloadable version is available to develop and test locally. When a required database setup has been created it may be scaled to the cloud service.
Creating a DynamoDB Table
To create a DynamoDB database table a database is not required to be downloaded and installed. Only an AWS account is required, which can be created at https://aws.amazon.com/. Select Services>Database>DynamoDB to create a database table.
Click on “Create table” in the DynamoDB getting started page.
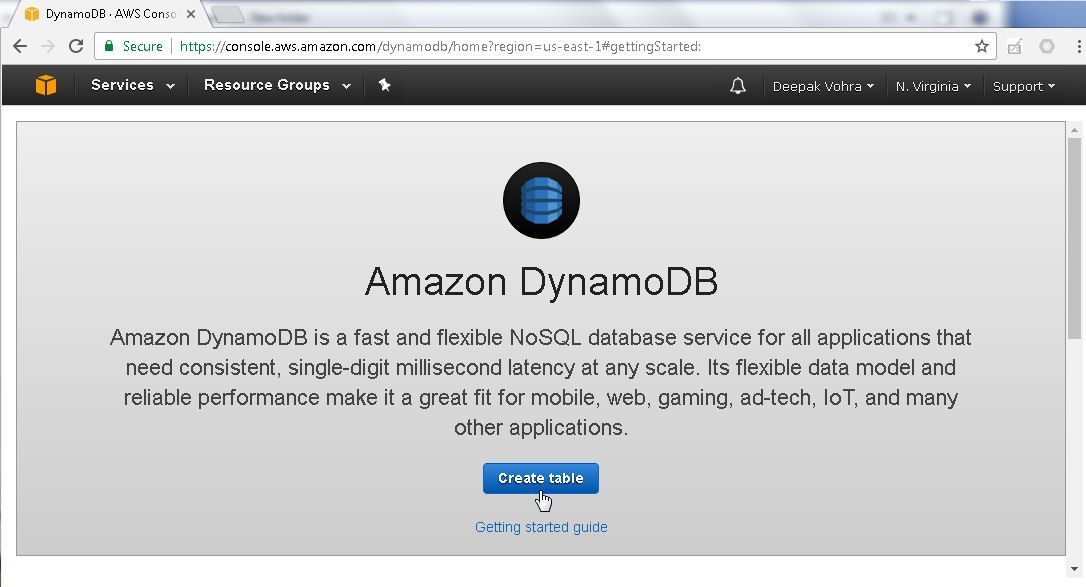
Specify a Table name (wlslog for example) and a Primary key, which is also the Partition key. These are the only two table attributes required to create a database table. The Primary key may be a simple primary key or a composite primary key. A simple primary key consists only of a partition key and a composite primary key consists of a sort key in addition to a partition key. The Use default settings are pre-selected. Click on Create.
Message "Table is being created" should get displayed. The required software and hardware resources get provisioned.
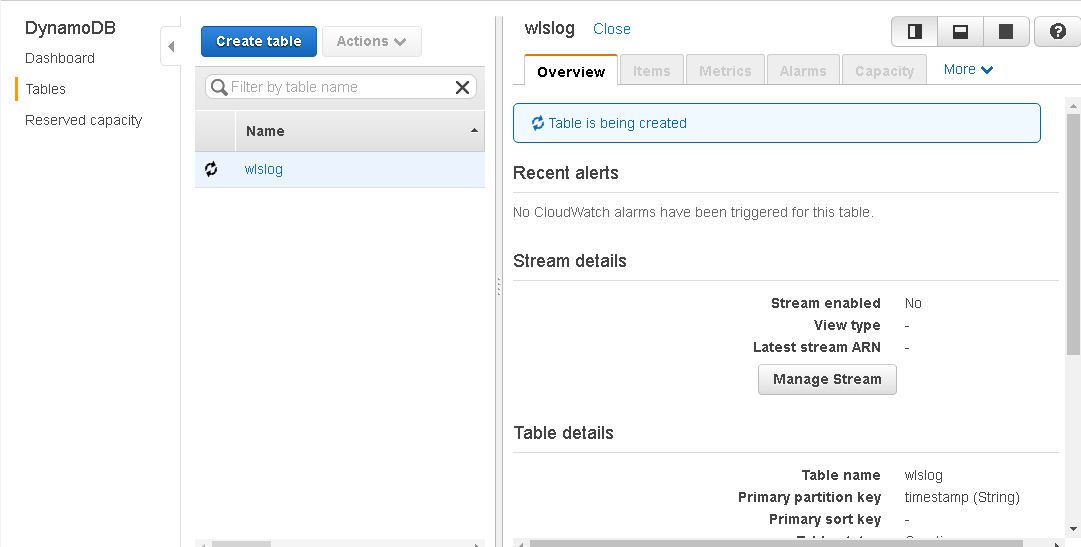
A DynamoDB table gets created. Initially the database table only includes a Primary Partition key.
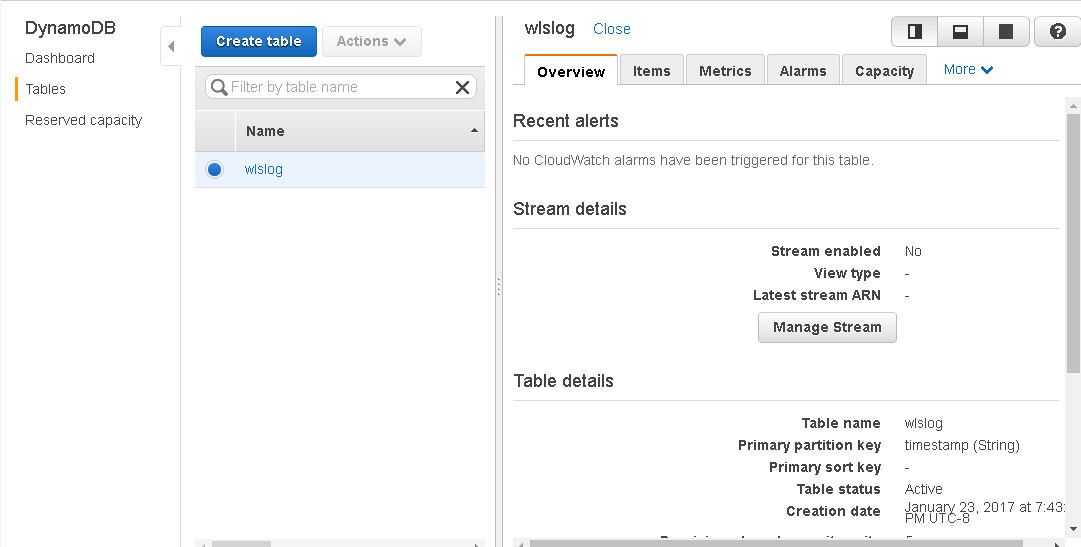
The Provisioned Read capacity and Provisioned Write capacity are each set to 5, which are the default settings. One read capacity unit implies one strongly consistent read per second or two eventually consistent reads per second for items up to 4KB. One write capacity unit implies one write per second for items up to 1KB.
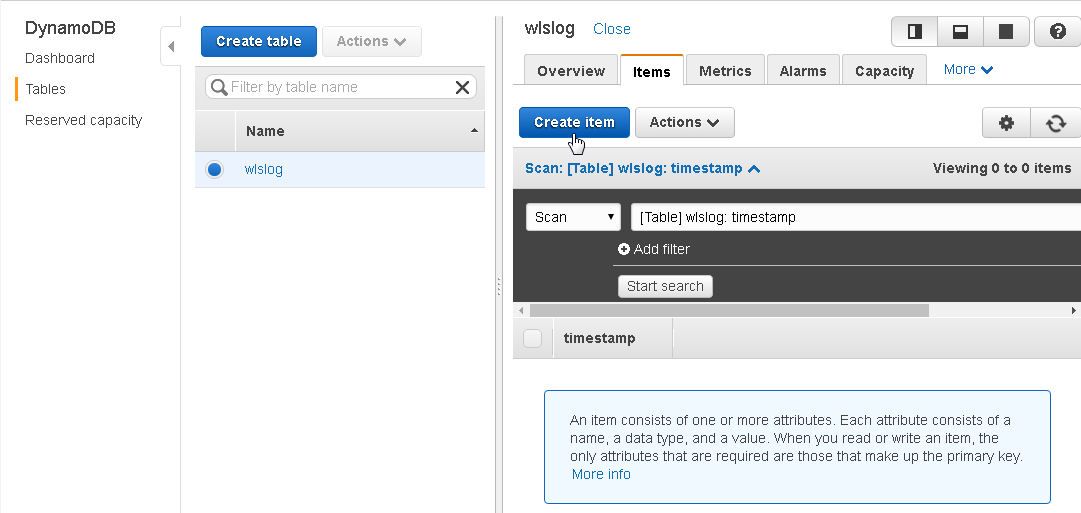
Next, we shall add an item to the wlslog table. The sample data we shall use is log data from a WebLogic server but another data set may be used instead. Click on Create Item to add an item. An item is just a collection of attributes, each of which has a name and a value. An item could be a scalar, set or document type.
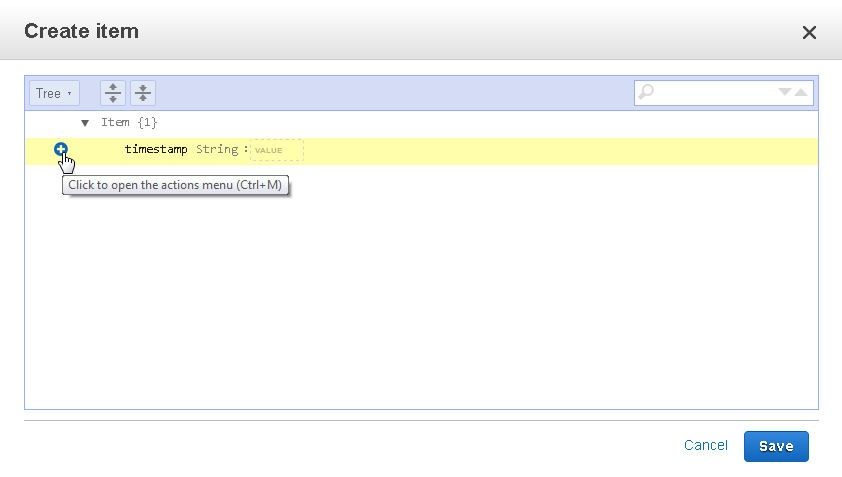
Next, add an item which consists of the following attribute names, all of type String (S).
"timestamp (S)","category (S)","code (S)","msg (S)","servername (S)","type (S)"
The primary key attribute is already in the item to create. Click on the + icon to append, insert, or remove an attribute. The item attributes are added in alphabetic order other than the primary key, which is always the first.
Click on Insert to add an attribute.
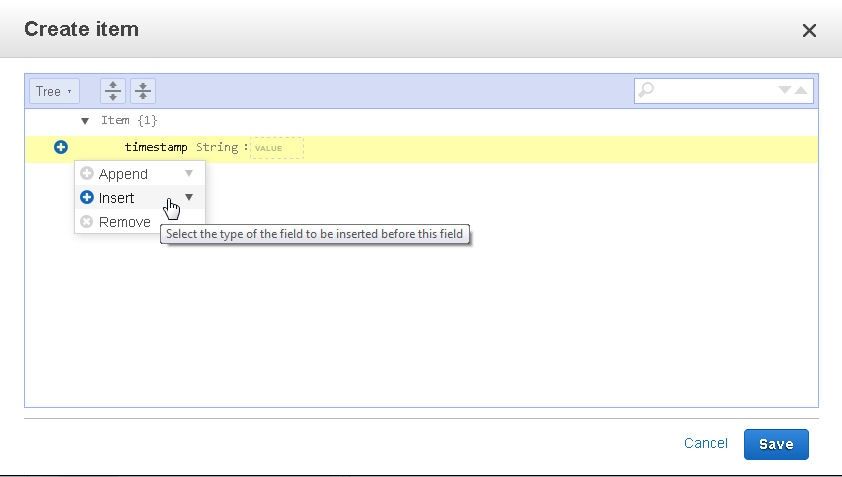
Select the attribute type from the list of available data types. Select "String" for the sample data.
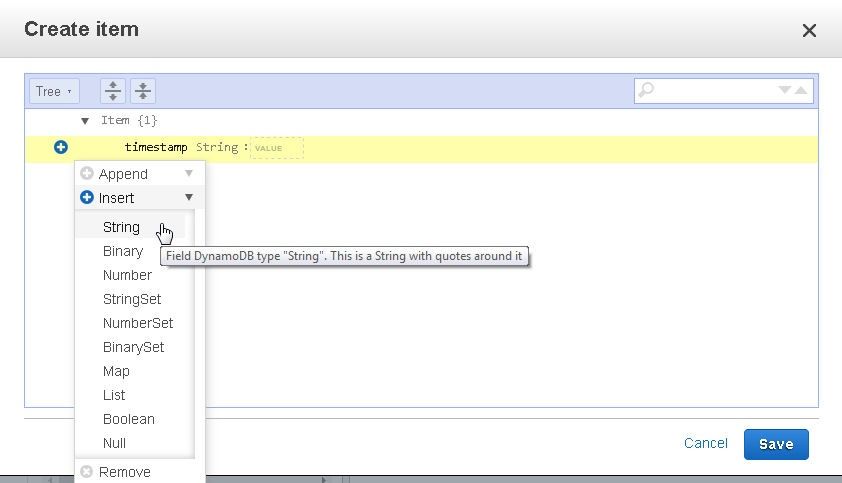
A new attribute of type String gets added. The attribute name field is empty and must be specified.
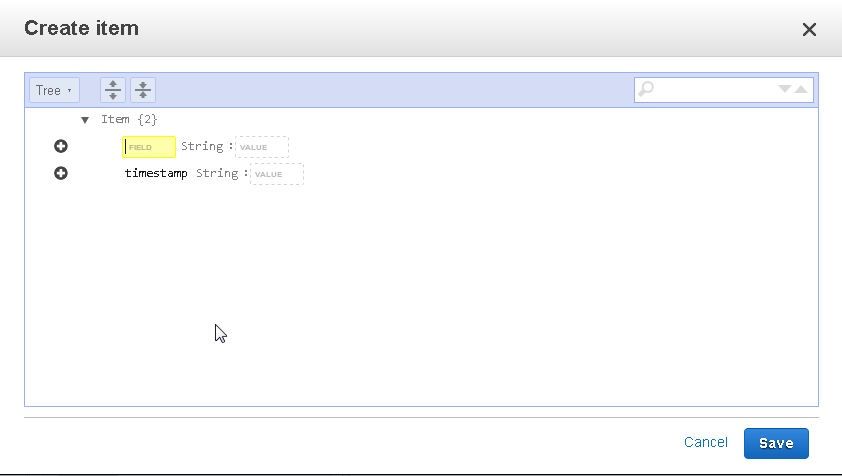
Next, we shall add attribute data for an item.
Apr-8-2014-7:06:16-PM-PDT,Notice,BEA-000365,Server state changed to STANDBY,AdminServer,WebLogicServer
Specify attribute name, “category”. By default the Tree view of an item is displayed.
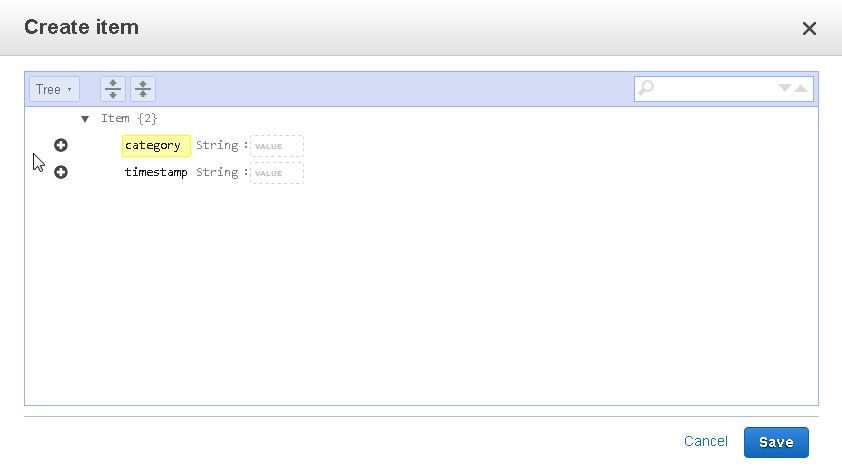
To display the JSON format of the item, select Text view and click on DynamoDB JSON. The error marker indicates that a value must be specified for the String.
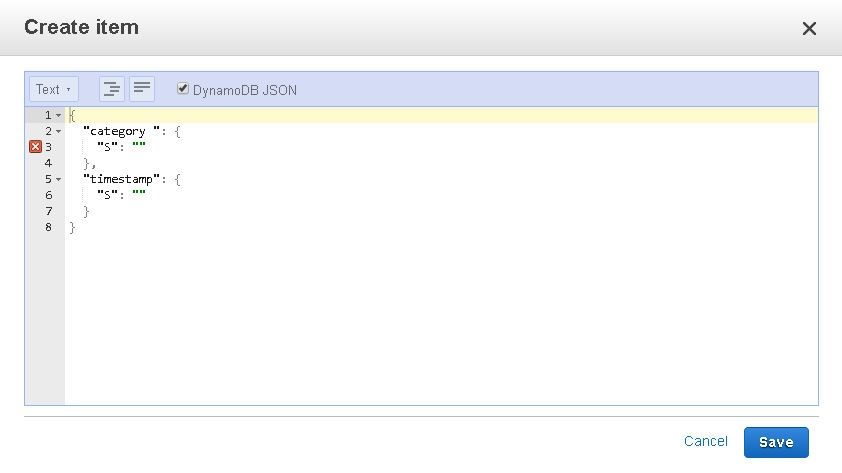
For adding a new item, the plain JSON format may be the most suitable. Deselect the DynamoDB JSON to display the plain JSON format. Add attributes for a complete item.
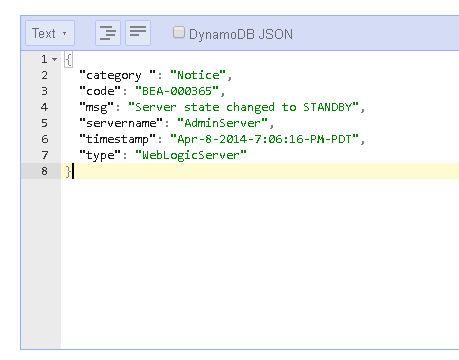
Click on Save. A new table item gets added.
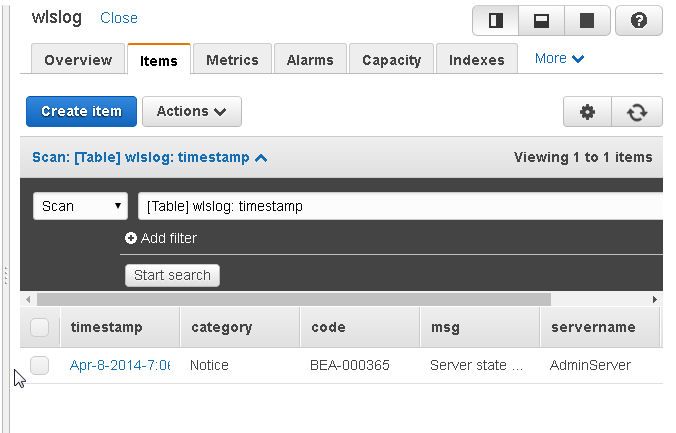
The new item may be edited by selecting Actions>Edit.
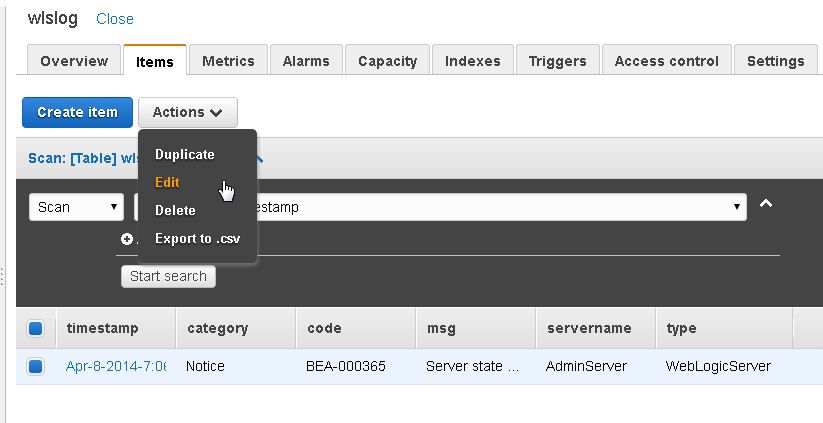
The Tree and Text views of the item may be toggled between. The Tree view of the same item is as follows.
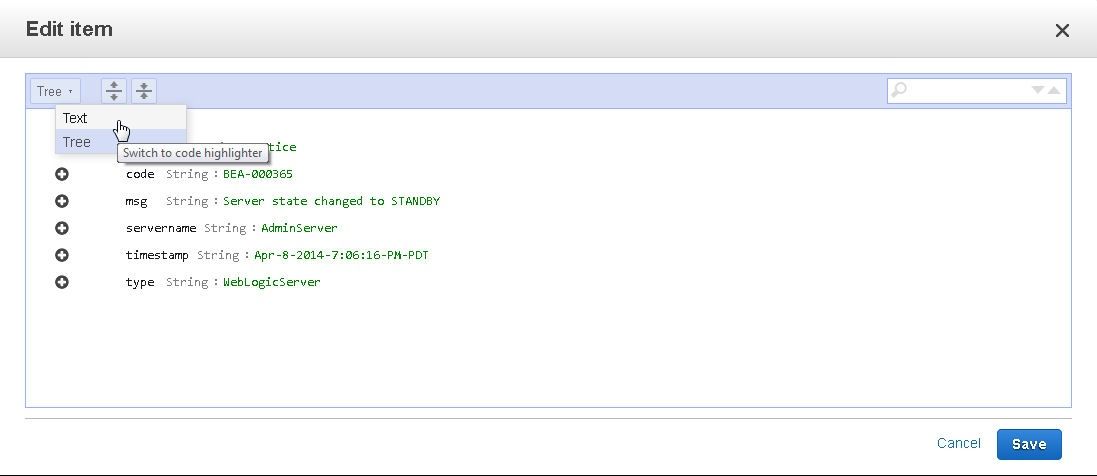
Similarly add more items.
"Apr-8-2014-7:06:17-PM-PDT","Notice","BEA-000365","Server state changed to STARTING","AdminServer","WebLogicServer"
"Apr-8-2014-7:06:18-PM-PDT","Notice","BEA-000365","Server state changed to ADMIN","AdminServer","WebLogicServer"
"Apr-8-2014-7:06:19-PM-PDT","Notice","BEA-000365","Server state changed to RESUMING","AdminServer","WebLogicServer"
"Apr-8-2014-7:06:20-PM-PDT","Notice","BEA-000331","Started WebLogic AdminServer","AdminServer","WebLogicServer"
"Apr-8-2014-7:06:21-PM-PDT","Notice","BEA-000365","Server state changed to RUNNING","AdminServer","WebLogicServer"
"Apr-8-2014-7:06:22-PM-PDT","Notice","BEA-000360","Server state changed to RUNNING mode","AdminServer","WebLogicServer"
An item may be added by selecting the plain JSON view in Text mode. Click on Save to save the item.
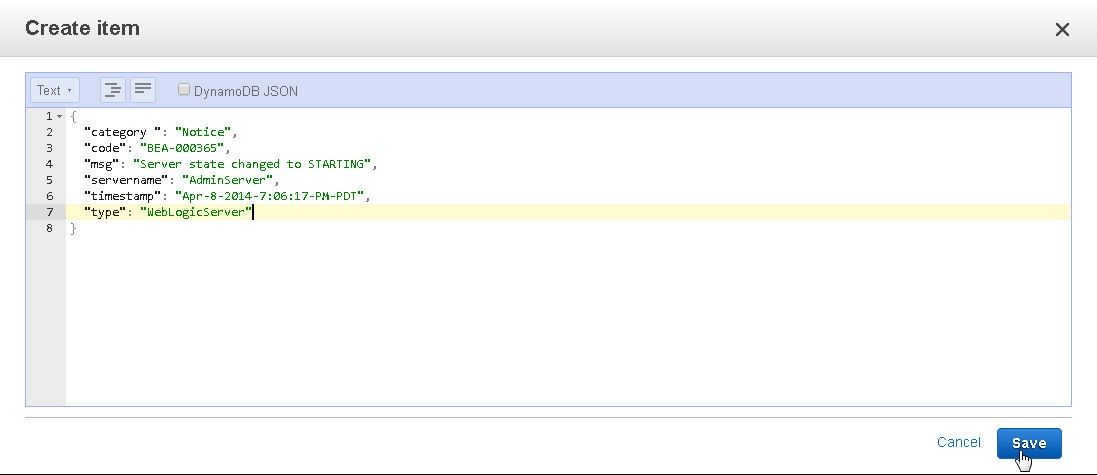
A wlslog table data gets created.
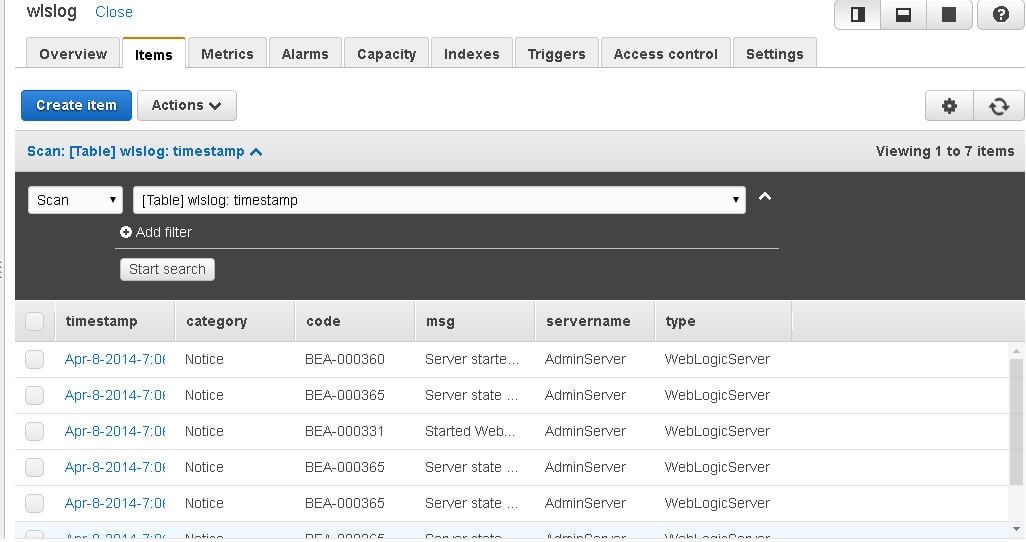
Click on the Scan: [Table] toggle link to display all the items.
In subsequent sections we shall scan and query the wlslog table. To delete the table select Actions>Delete table. The table may also be imported or exported with the Actions>Import and Export selections, respectively.
Scanning a Database Table
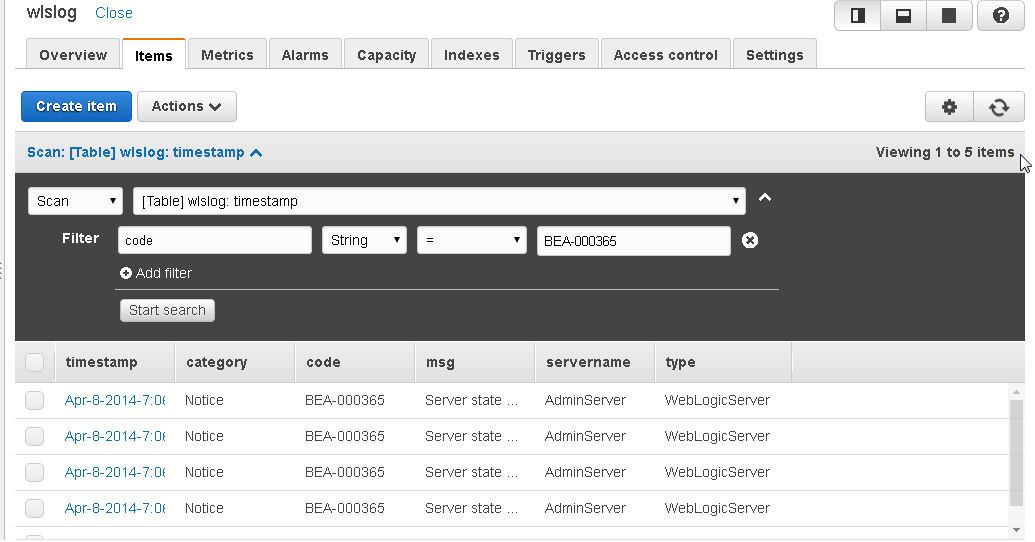
The default view of the table data is Scan. A filter may be added to scan a subset of data. For example, scan only for items with “code” attribute as “BEA-000365”. Click on Start search to display the result. Only 5 items get displayed.
Click on the Scan: [Table] toggle link to display all the items. The Scan result set is always generated, even for an empty result set.
Querying a Database Table
The difference between a Query and a Scan is that, while a Scan scans the entire table, a Query finds item/s based only on primary key attribute value/s. The partition key must be specified for a Query and the Sort key may optionally be specified also. A DynamoDB table may be queried by selecting Query.
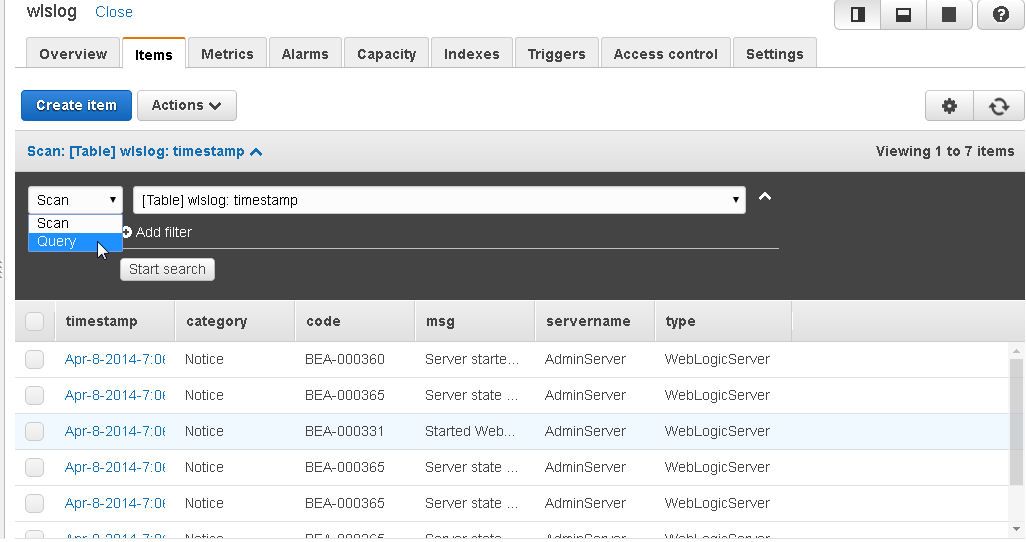
A Filter may also be added for a Query. As an example, Query with Partition key as “Apr-8-2014-7:06:16-PM-PDT” and Filter as code=BEA-000365.
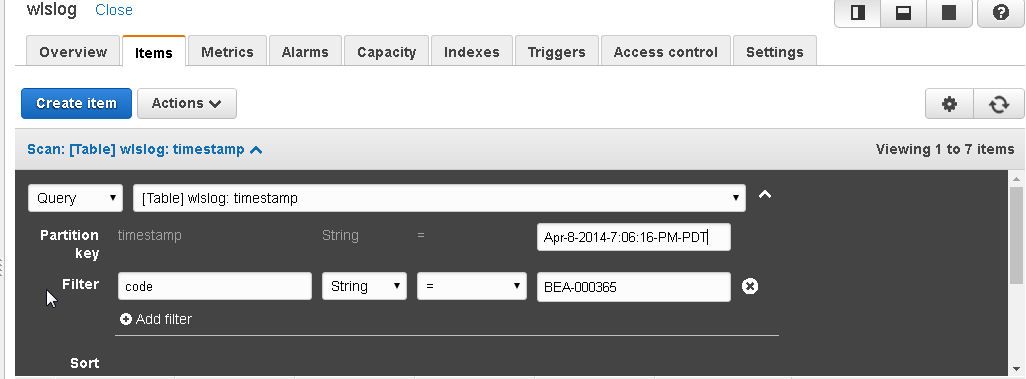
The Query result set, which is always displayed even for an empty result set, displays one item.
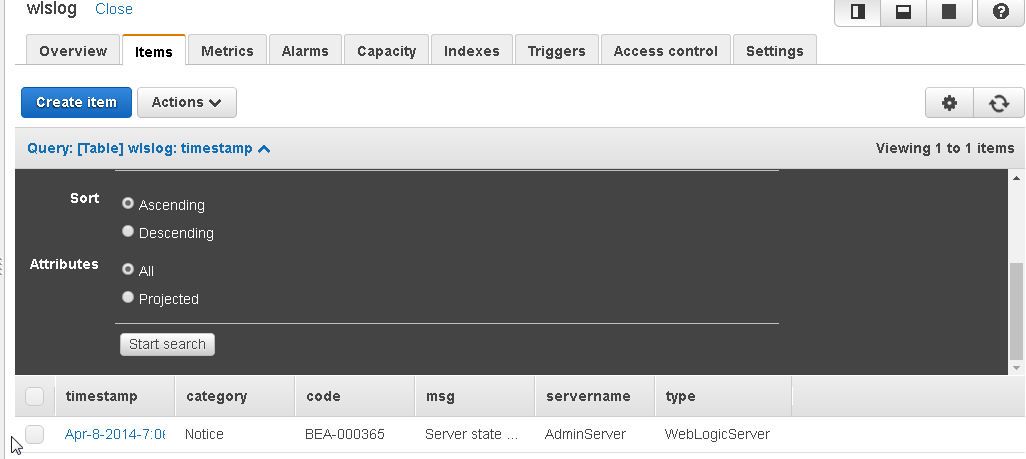
Exporting DynamoDB Table Data to a CSV File
To export the result set of a Scan or a Query to a CSV file select the items to export and click on Actions>Export to .csv.
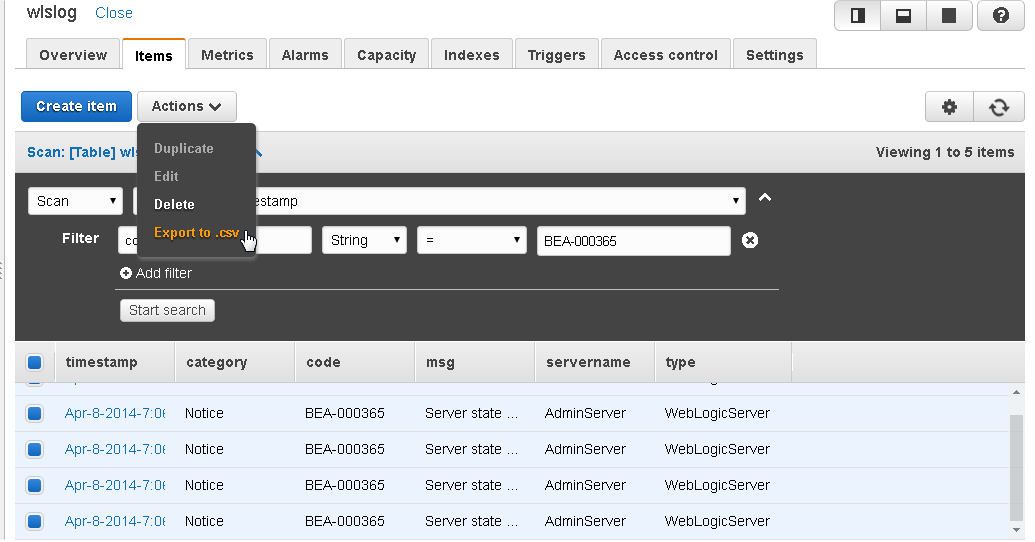
A wlslog.csv file gets exported. The .csv file name is the same as the table name.
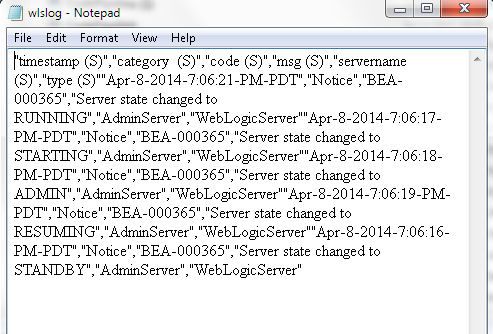
Loading Exported CSV Data into a MySQL Database Table
In this section we shall load the CSV data exported from a DynamoDB table into a MYSQL database table. Start a MySQL database command line interface (CLI).
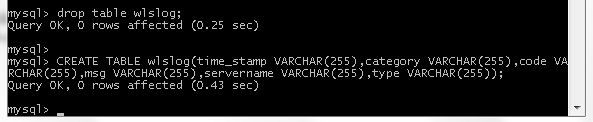
We shall use the LOAD DATA LOCAL INFILE command to load data into a MYSQL database table. Create a MySQL database table called wlslog in which the column names are in alphabetic order.
CREATE TABLE wlslog(time_stamp VARCHAR(255),category VARCHAR(255),code VARCHAR(255),msg VARCHAR(255),
servername VARCHAR(255),type VARCHAR(255));
A requirement of the LOAD DATA LOCAL INFILE command is that the table to load the data into must have been created.
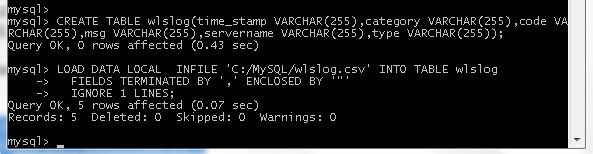
Run the following command to load data from the 'C:/MySQL/wlslog.csv’ file into the wlslog database table. The line 1 in the wlslog.csv is for attribute names and is not to be loaded.
LOAD DATA LOCAL INFILE 'C:/MySQL/wlslog.csv' INTO TABLE wlslog
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
IGNORE 1 LINES;
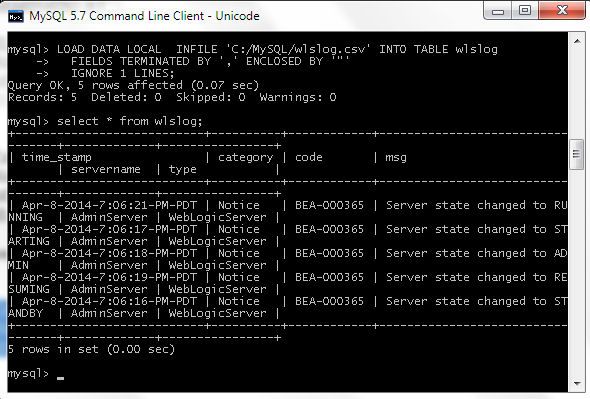
The CSV data gets loaded into the wlslog table.
Run a SELECT statement to query the database table and list the data added.
In this article we introduced DynamoDB, a fully managed, fast, highly scalable, reliable NoSQL database service hosted on the AWS cloud. DynamoDB is suitable for web scale applications and not a general purpose database for all kinds of applications. Relational databases such as Amazon RDS (Relational Database Service) should be used for a relatively small scale database in which complex transactions and complex relational queries are important, and high scalability is not required.
Start the discussion at forums.toadworld.com