Amazon Web Services or AWS, launched officially in 2006, is a subsidiary of the online giant Amazon.com and was set up specifically for providing (at a price) Infrastructure as a Service (IaaS) cloud capabilities to the outside world. This meant virtual machines that could be provisioned rapidly in AWS data centers around the world, and is based on a pay-as-you-go model (with possibilities for paying in advance). AWS Elastic Compute Cloud (EC2) and Simple Storage Service (S3) were among the IaaS services made available by AWS. Elastic Block Store (EBS) was added two years later, this was block-level storage and allowed “persistent” storage for EC2 instances; the feature had been lacking when EC2 was first launched. AWS has grown rapidly in the last ten years since the first days in 2006, and can now be said to be the market leader in the Cloud Infrastructure services space.
Initially AWS was used by IT workers and sales engineers who wanted to test or demonstrate new features or demo their software. Even large software vendor companies such as Oracle were using AWS for its product demos until a few years ago. Instead of the sales engineers setting up servers for a workshop, installing software on each server, and then using it for a test or a demo or workshop, they used AWS. This was an excellent, fast way of starting up one or more pre-installed virtual machines, and using these for the demo or workshop. All that was needed was a corporate credit card.
Developers were also among the first to use AWS for their development activities due to its low cost, and over the years, companies started to migrate their test or development servers to AWS. Today, we can look around and see entire production data centers being moved lock, stock and barrel to AWS. Using the cloud for production servers is gaining acceptance even in large corporations. AWS reports in its seminars that financial institutions are also journeying to the AWS cloud, and one example is DBS bank in Singapore, which has recently openly declared that it intends to move 50% of its compute workload to the AWS cloud with the next two years. Other banks are using AWS for development/test, or analytics of customers and marketing, risk management, digital/mobile banking, blockchain, IoT via Alexa/Echo (such as asking for quotes), or even core banking systems as well as disaster recovery in a few cases.
Xen virtualization is used for the virtual machines in EC2. Note that to date AWS does not provide any “bare metal” compute service, which is dedicated physical server hardware without the performance overhead of virtualization, and where you can reuse your existing server licenses subject to existing licensing terms. Bare metal compute services are available in the Oracle compute cloud.
Coming back to our historical journey, for database demos and tests, initially the people who were using AWS installed their own database software on the provided virtual servers, and created the databases they wanted. However, down the track, in 2009, AWS released the Amazon Relational Database Service (Amazon RDS). This was technically “Database as a Service” (DBaaS) instead of Infrastructure as a Service, and made it very easy to use AWS to create a new database server with the database software pre-installed. The database itself was created when requesting the service.
In the RDS service, database administration activities such as backup and patching the database software would be managed by AWS. Initially, Amazon RDS supported MySQL, followed by the Oracle database, MS SQL server, PostgreSQL and MariaDB, the last being a fork of MySQL.
AWS by now had realized the potential for a “cloud-optimized” database, and after five years of investigating the possibilities of optimizing database for the cloud, decided to release Amazon Aurora in 2014. This was a MySQL-compatible database designed and optimized for the cloud, and it was feature-compatible with version 5.6 of MySQL.
The goal was to improve the price-performance ratio for DBaaS users. The primary technique used to achieve this was to move the logging and storage layer into a multi-tenant and database-optimized storage service, Amazon S3 – that could scale out on demand, and integrate with other AWS services. This is seen in Figure 1 below.
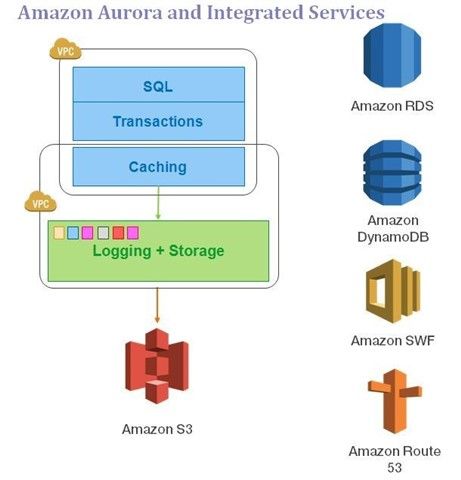
Figure 1: Amazon Aurora and Integrated Services.
Since storage was decoupled and cloud storage was used, it could easily scale. In the case of Amazon Aurora the storage scales automatically on SSD storage arrays in 10GB increments as needed, and can go up to 64TB. The storage used for an Aurora database is automatically replicated across three AWS Availability Zones (AZs). There are two copies of the data in each Availability Zone. This kind of architecture for the storage gives it considerable durability and high availability up to 99.99%. Recovery from instance and storage failures takes place automatically.
Also, the Aurora database doesn’t wait for all writes to finish, only four out of six writes need to be complete. This is known as a “quorum” type of write and effectively eliminates hot spots. The storage architecture also means that backups to the Amazon Simple Storage Service (S3) are rapid, parallelized and continuous, with no performance impact on the database instance server. Automatic, worry-free database backups are truly a DBA’s dream. If needed, the DBA can restore the database to a previous point of time up to any second if so required.
The other advantage is that from the primary database, up to 15 Amazon Read replicas can be created (manually, not automatically). These read replicas can be used for reads by the application, and can also be used to failover to. These read replicas share storage with the primary database, so the replication to the replicas is fine-grained and almost synchronous, with a lag of about 10 to 20 milliseconds.
Note however that the application must be told where to read from and where to write to, and this will be a manual modification. Only certain web/application servers which are set up to use the read replicas will need to handle the read queries, and only the web/application servers talking to the primary instance should handle the writes needed by the application.
The use of read replicas is therefore obviously not transparent to the application, as it would be in a true active-active read-write cluster. This can be considered a drawback – since it means that there is no “auto-scaling” as such in the case of writes to the database. One option could be to move your primary database to a more powerful database server instance, but that means vertical scaling, downtime, and for some of us it brings back memories of an earlier age where hardware companies asked clients to migrate from one database server to another more powerful database server. Many felt that horizontal scaling and active-active database clustering solved that issue. But in the case of Amazon Aurora, obviously there is no active-active database clustering.
To facilitate migration to the Aurora MySQL-compatible database, AWS created a database migration service and a schema conversion tool. These have some good capabilities, but they also have some drawbacks. More on that in Part II of this article series. Part II has been posted here.
(Disclaimer: The views expressed in this article are the author’s own views and do not reflect the views of Amazon Web Services (AWS) or Oracle Corporation. The author as of February 2017 is not affiliated or employed by either AWS or Oracle. The author has been a past employee of Oracle and at this point of time is an independent, unbiased cloud architect/consultant.)
Start the discussion at forums.toadworld.com