I. Introduction
In the IT industry we go through a tedious and long process of acquiring infrastructure (hardware software and licenses). Typically, projects are held back due to infrastructure delays in definition, contracts, support and licenses. Oftentimes, projects have been cancelled due to the infrastructure cost and non-ability of escalation. Cloud computing addresses all these difficulties and more. Teams now can focus in more important aspects of the projects: business, functionalities, and applications; and pay little heed to the infrastructure, which is totally or partially managed by the cloud provider. Everything from storage for petabytes of data to high compute capacity is at your disposals. You have the software, hardware, all on demand and at your disposals everywhere and anytime, with the ability to scale, and at lower cost.
This article is the first of a series on Big Data in the cloud. In it, we will introduce the Big Data warehouse service in AWS. We will learn the Redshift architecture and good practices to maximize the usage of the Big Data Warehouse service in the cloud.
II. Amazon Redshift
Amazon Redshift is a very powerful and fast relational data warehouse in the AWS cloud. Easy to scale to petabytes of data, it is optimized for high- performance analysis and reporting of very large datasets. Amazon Redshift is specifically designed for online analytic processing (OLAP) and business intelligence (BI) applications, which require complex queries against large datasets.
Amazon Redshift offers fast querying using the most commonly query language; SQL. Clients use ODBC or JDBC to connect to Amazon Redshift. Amazon Redshift is based on PostgreSQL. Amazon Redshift and PostgreSQL have a number of very important differences that you must be aware of as you design and develop your data warehouse applications; for example, PostgreSQL 9.x includes some features that are not supported in Amazon Redshift.
Refer to http://docs.aws.amazon.com/redshift/latest/dg/c_unsupported-postgresql-features.html for a complete list of non-supported PostgreSQL features in Amazon Redshift.
Amazon Redshift can be scaled out easily by resizing the cluster. Redshift will create a new cluster and migrate data from an old cluster to the new one. During a resize operation, the database will become read only. The Amazon Redshift service offers automation of administrative tasks such as snapshot backups and patching, along with tools to monitor the cluster and to recover from failures.
III. Amazon Redshift Cluster Architecture:
The main component of an Amazon Redshift is the cluster, which is composed of a leader node and one or more compute nodes. When the clients or the application establishes a connection to the Amazon Redshift Cluster, it connects directly to the leader node only. For each SQL query issued by the users, the leader node calculates the plan to retrieve the data. It passes that execution plan to each compute node, and each slice processes its portion of the data. The leader node manages the distribution of data and query processing tasks to the compute nodes.
Amazon Redshift currently supports six different node types; each node type differs from others in vCPU, memory and storage capacity. The cost of your cluster depends on the region, node type, number of nodes, and whether the nodes are reserved in advance. The six node types are grouped into two categories: Dense Compute and Dense Storage. The Dense Compute node types support clusters up to 326TB using fast SDDs. The Dense Storage nodes support clusters up to 2PB using large magnetic disks.
The following tables describe every node type. Check http://docs.aws.amazon.com/redshift/latest/mgmt/working-with-clusters.html for more details about the node types.
Dense Compute Node Types
|
Node Size |
vCPU |
ECU |
RAM (GB) |
Slices Per Node |
Storage Per Node |
Node Range |
Total Capacity |
|
dc1.large |
2 |
7 |
15 |
2 |
160 GB SSD |
1–32 |
5.12 TB |
|
dc1.8xlarge |
32 |
104 |
244 |
32 |
2.56 TB SSD |
2–128 |
326 TB |
Dense Storage Node Types
|
Node Size |
vCPU |
ECU |
RAM (GB) |
Slices Per Node |
Storage Per Node |
Node Range |
Total Capacity |
|
ds1.xlarge |
2 |
4.4 |
15 |
2 |
2 TB HDD |
1–32 |
64 TB |
|
ds1.8xlarge |
16 |
35 |
120 |
16 |
16 TB HDD |
2–128 |
2 PB |
|
ds2.xlarge |
4 |
13 |
31 |
2 |
2 TB HDD |
1–32 |
64 TB |
|
ds2.8xlarge |
36 |
119 |
244 |
16 |
16 TB HDD |
2–128 |
2 PB |
The following diagram explains the architecture of Amazon Redshift
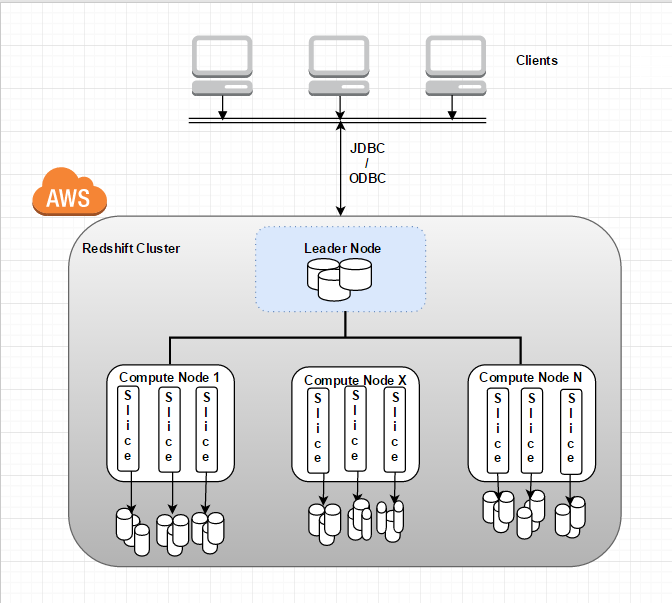
Each Redshift cluster is a container of one or many databases. The data of each table is distributed across the compute nodes. The storage of every compute node is divided into slices. The number of slices per node depends on the node size of the cluster. For example, each DS1.XL compute node has two slices, and each DS1.8XL compute node has 16 slices. When the application issues a query against the Redshift cluster, all the compute nodes participate in parallel processing.
IV. Amazon Redshift Cluster Setup
In this exercise, we will setup a 4 node Redshift cluster from the AWS console.
- First login to the console: Open the AWS Management Console and login to http://console.aws.amazon.com
- Find the Redshift service link from the Services menu: Click on Redshift
3. Click on Launch Cluster
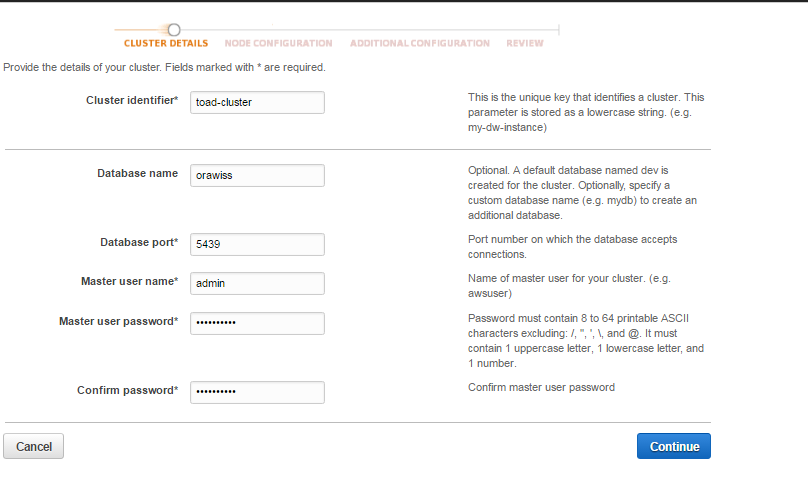
4. A cluster details page will show up; insert the cluster identifier and the database name that you want to be created during cluster setup process. The port number per default is 5439; you need to allow inbound in the security group to allow users connect to your cluster. Choose the admin user and password, then click on continue.
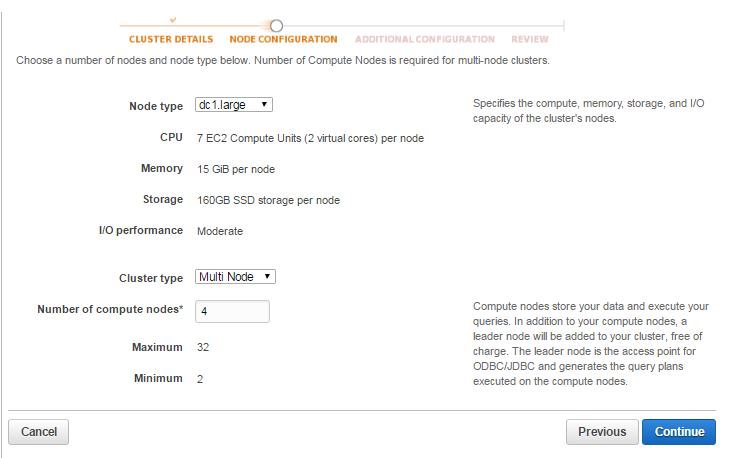
5. Choose the node type according to your workload, the multi node cluster type and the number of compute nodes. Click on Continue.
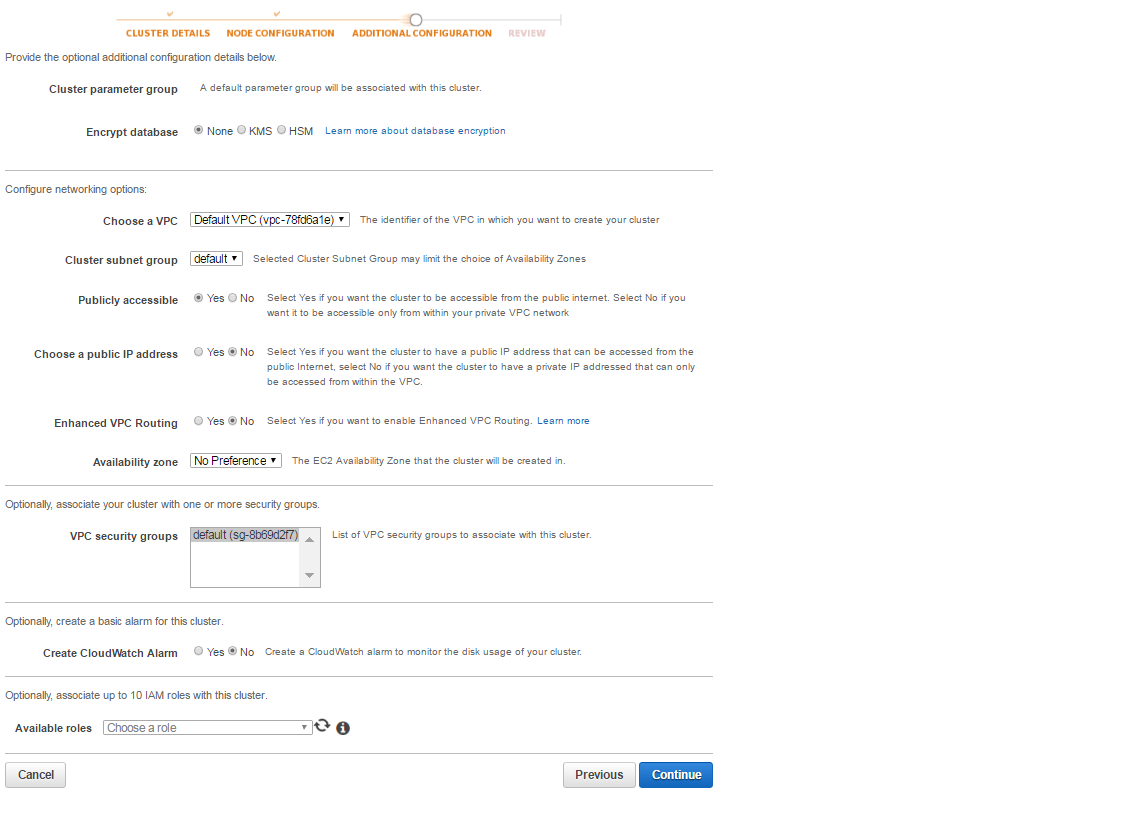
6. At this step, it is recommended to setup your cluster in your own VPC; do not allow public access to your cluster and choose appropriate security group to filter and secure the traffic into your cluster.
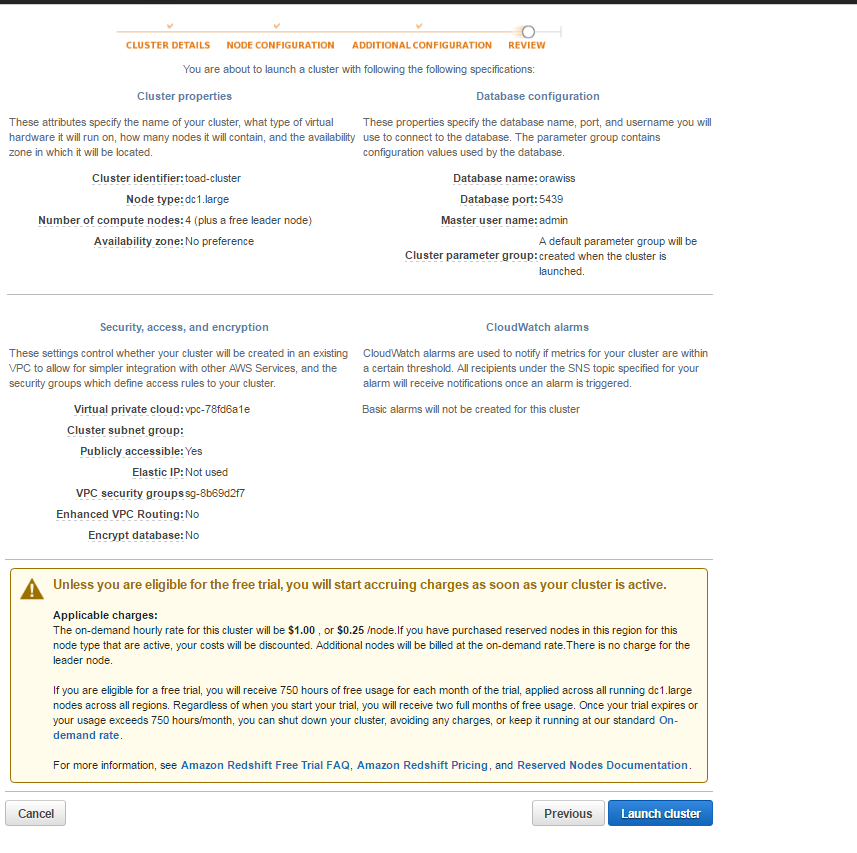
7. In this step, you will see a summary of your cluster setup. Click on launch cluster.
8. It will take about 10 to 20 minutes to get your cluster up and running. Take a note of the JDBC URL. We will use the JDBC URL to connect remotely to the Redshift cluster.
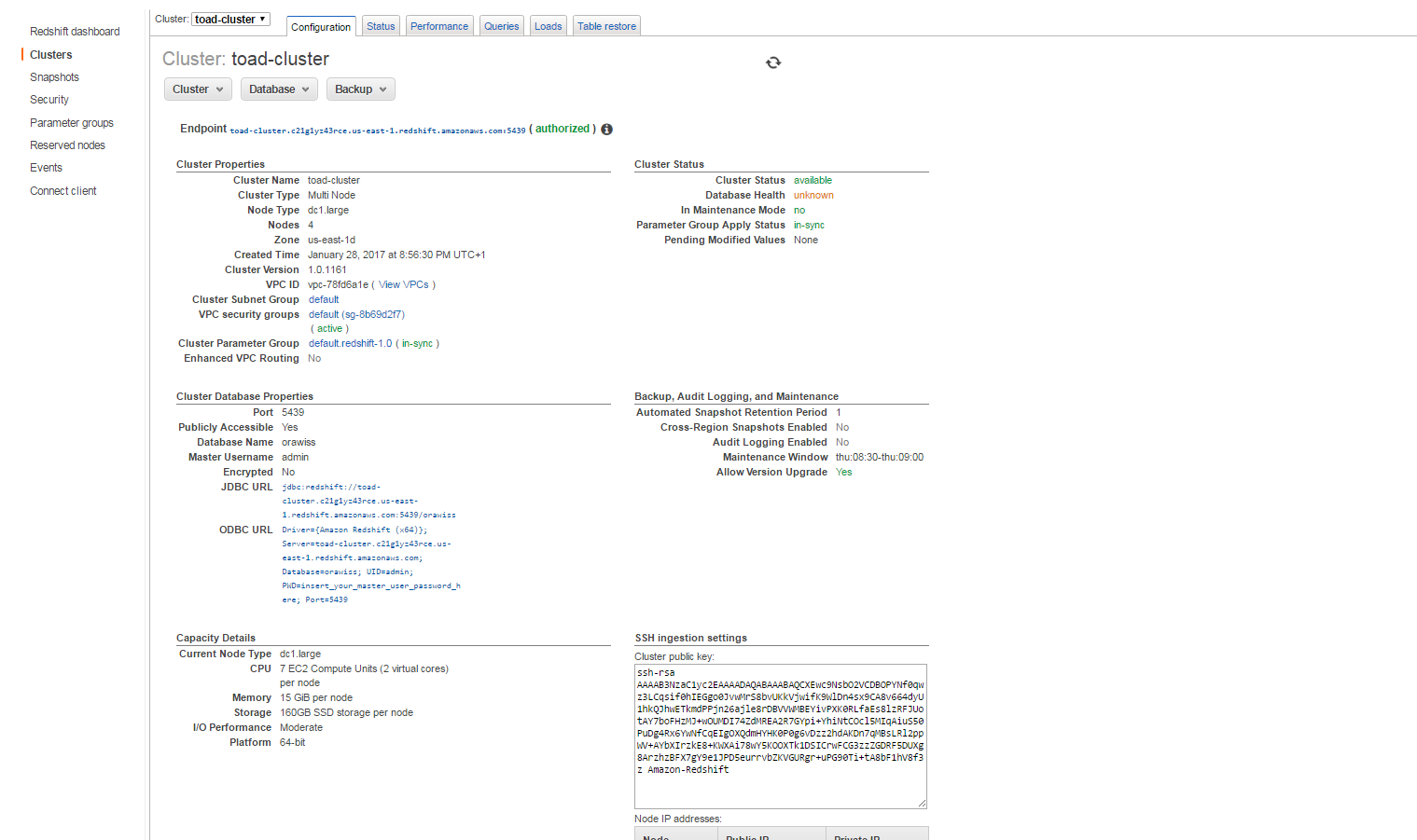
V. Connect to the Redshift Cluster using SQL Workbench/J
In this section, we will use SQL Workbench/J, a free SQL client tool.
1. Install SQL Workbench/J tool:
In order to connect to your Amazon Redshift cluster, you need to download
- The SQL Workbench/J; for example, Download generic package for all systems that you can find here: http://www.sql-workbench.net/downloads.html
- The Amazon Redshift JDBC Driver; you can download from here: http://docs.aws.amazon.com/redshift/latest/mgmt/configure-jdbc-connection.html#download-jdbc-driver
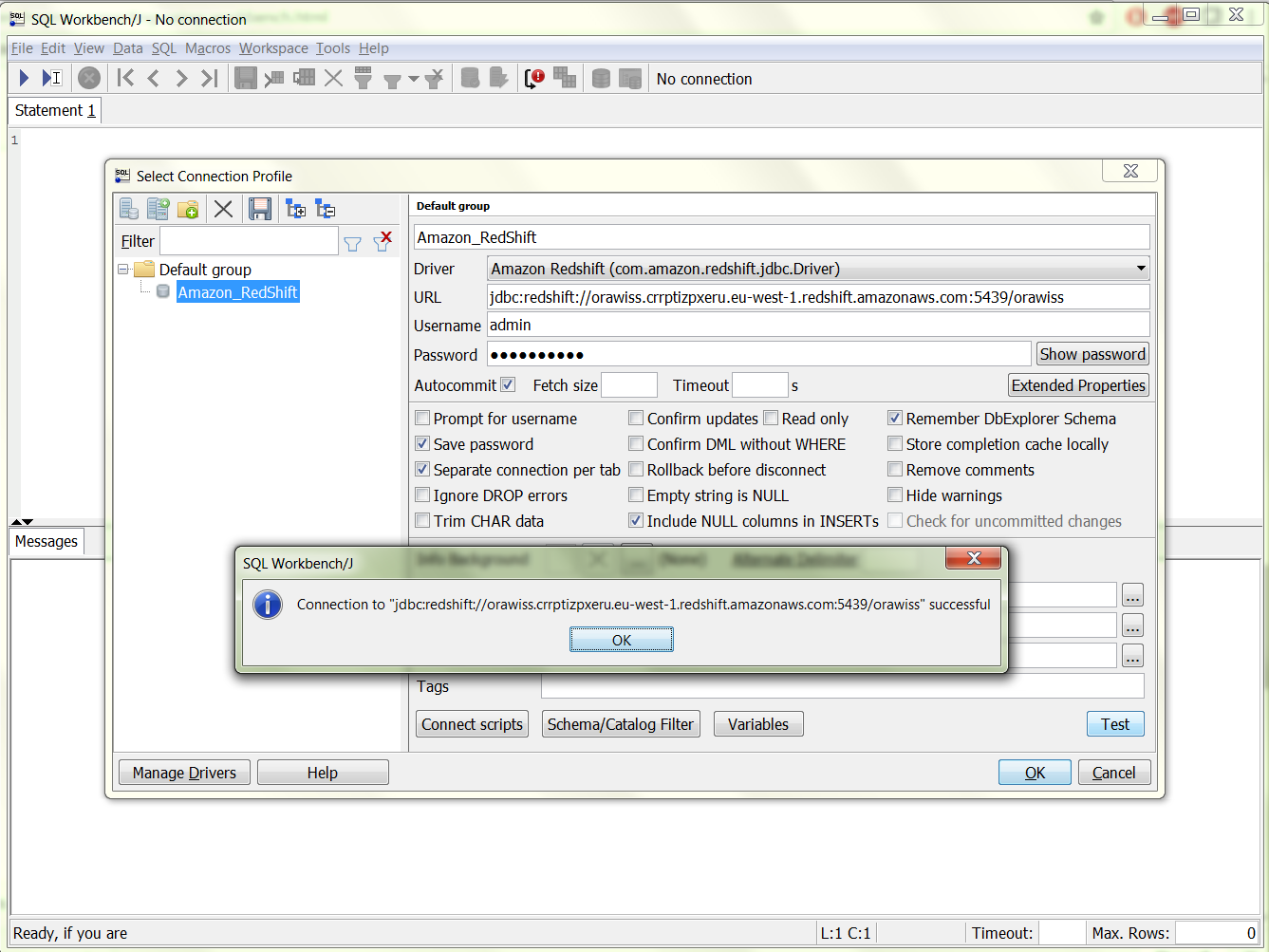
2. Connect to the Redshift Cluster:
- Open SQL Workbench/J, Click File, and then click Connect window. Then click Create a new connection profile.
- In the New profile box, type a name for the profile. For example, Amazon_Redshift.
- Click Manage Drivers. The Manage Drivers dialog opens. In the Name box, type a name for the driver, example: Amazon Redshift.
- In URL, copy the JDBC URL from the Amazon Redshift console
- In Username, type the name of the master user. In our case, it is admin
- In Password, type the password associated with the master user account.
- Select the Auto commit box.
- Click on Test to test the connection.
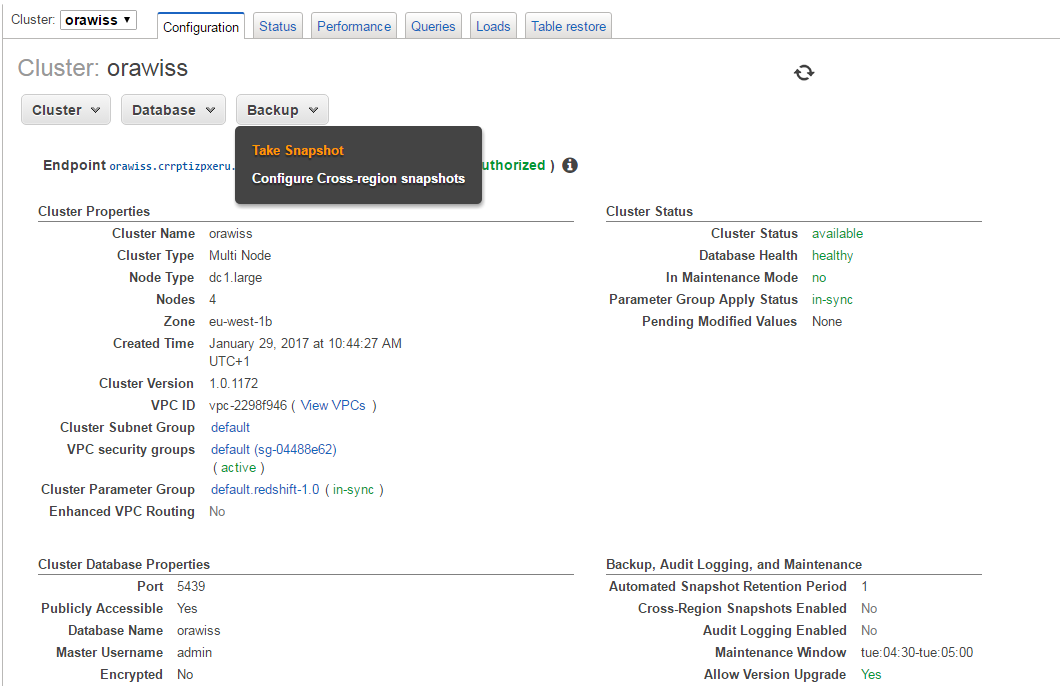
VI. Amazon Redshift Cluster Backup
Amazon Redshift Cluster backup is automatically enabled using snapshots. You can also manually backup your databases by taking a snapshot. Sign in to the AWS Management Console and open the Amazon Redshift console at https://console.aws.amazon.com/redshift/. In the cluster configuration tab, click on Backup and select Take Snapshot.
VII. Conclusion
In this article we introduced the Amazon Redshift architecture and cluster build; we have seen the simplicity and power of the Big Data Warehouse service in the Amazon Cloud. In the next article of the series, we will explore the Amazon Redshift Database design and examples of query performance.
Start the discussion at forums.toadworld.com