Introduction
When writing a normal SQL query, the user is typically working in a SQL authoring program that is connected directly to the RDBMS in which the query will be run.
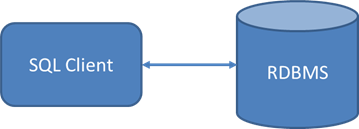 1 – Simple Client Connection
1 – Simple Client ConnectionThis means when the query is executed in three steps:
- A small amount of query text is sent over the network from the SQL client to the RDBMS.
- All data scanning, filtering, sorting and grouping is done locally within the RDBMS.
- The result set is returned over the network to the SQL client program.
There are only two real opportunities for latency in this simple scenario. If the query or database schema is poorly structured – commonly problems like failure of the SQL to use an index or missing indexes in the schema – then the RDBMS may not be able to execute the SQL efficiently in step 2.
Alternately, if the query returns a large amount of data, then step 3 may take a long time depending upon the speed of the network link between the SQL client and the RDBMS. Indeed, if the query is executed efficiently, then copying the data from the RDBMS to the SQL Client will consume most of the end-to-end query execution time.
The execution of a cross-database query is much more complex. This gives rise to commensurately more opportunities for execution of the query to become inefficient. The environment in which a cross-database query runs has many moving parts compared with a simple client connection.
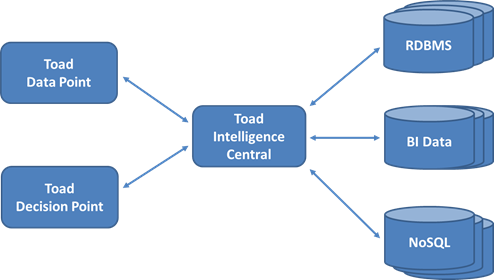 2 – Multi-Database Connection
2 – Multi-Database ConnectionFigure 2 depicts the Toad Intelligence Central server being connected to multiple databases, with a cross-database query being authored in either a Toad Data Point or Toad Decision Point client. The steps to execute a cross-database query are:
- A small amount of query text is sent over the network from the Toad client to Intelligence Central.
- Intelligence Central deconstructs the query into sub-queries to fetch data from the various remote databases that are being accessed.
- Intelligence Central executes the sub-queries against the remote databases and fetches a discrete result set for each sub-query.
- Intelligence Central uses the join criteria from the original query to merge all the discrete result sets into a single cross-database result set.
- Intelligence Central applies post-join filtering, sorting and grouping to the merged results.
- The cross-database result set is returned over the network to the SQL client program.
So, what could go wrong? For starters, even a simple SQL query that only fetches data from one database would incur the overhead of copying the query’s result data across the network twice. Once from the remote database to Intelligence Central, and again from Intelligence Central to the Toad client. Therefore a single-database query will always be more efficiently executed with a direct client connection to the target database.
Step 2 sees Intelligence Central use the data source and table mapping configuration to determine how to deconstruct the cross-database query into a sub-query for each database that is contributing data to the results. The main risk here is that the process of splitting up the query may not generate the most efficient set of sub-queries that is possible. Intelligence Central uses several methods of optimizing the sub-queries to minimize the amount of data that is copied from the remote databases, because this is probably going to make up at least 50% of the total query’s execution time.
These methods are described in detail below in Optimizing a Cross-Database Query. The ability of Intelligence Central to apply these optimizations is very sensitive to the way the cross-database SQL query is written. So each optimization is described in detail, together with samples of what to do, and what not to do!
Step 3 relates to the execution of the sub-queries to fetch results from the referenced databases. One thing to bear in mind here is that Intelligence Central will use SQL to fetch data from RDBMS databases, but will typically use a REST-based web service to access NoSQL or Business Intelligence data sources via HTTP. These REST interfaces are usually slower than SQL because the data must be unpacked from an HTTP response packet, which often requires XML parsing.
The final point to make is that with a cross-database query, the process of scanning for data to include in the query, then filtering it with conditions from the WHERE clause, and finally grouping and sorting the output, is distributed across several databases and applications. Contrast this with a SQL query against a single RDBMS whose SQL optimizer can leverage its knowledge of the indexes, data sizes, and possibly even data locality, to execute the entire query within the memory and compute space of a single process.
So to get the best results from writing a cross-database query, you must consider how Intelligence Central is going to break up and execute your query, and make sure you allow Intelligence Central to use all the optimizations that it possibly can.
Optimizing a Cross-Database Query
Group Related Tables
One of the major performance bottlenecks in a cross-database query occurs when Intelligence Central has to execute multiple sub-queries against the same relational database. Consider this query:
SELECT c.customer_name, s.sales_amount, s.sales_quantity
FROM sales_db.sales s
JOIN cust_db.customer c ON c.customer_key = s.customer_key
JOIN cust_db.geography g ON g.geography_key = c.geography_key
WHERE g.country_name = 'Japan'
Because each of the tables from the customer database are joined individually to the sales table, Intelligence Central will execute two separate sub-queries against the customer database. The first will fetch all customer data. The second will fetch geographical locations whose country is set to “Japan”. These two datasets will subsequently be joined when Intelligence Central merges all the sub-query results into a single cross-database result set. If there are many customers in this database then this is a very expensive way to process the query.
A better way to structure this query is to use a SQL in-line view to group the related tables into a single sub-query to the customer database:
SELECT x.customer_name, s.sales_amount, s.sales_quantity
FROM sales_db.sales s
JOIN (
SELECT c.customer_key, c.customer_name
FROM cust_db.customer c
JOIN cust_db.geography g ON g.geography_key = c.geography_key
WHERE g.country_name = 'Japan'
) x ON x.customer_key = s.customer_key
Grouping these two tables with an in-line view allows Intelligence Central to push down a single query to the customer database, which retrieves only the key and name of those customers who are located in Japan.
Filter, Filter, Filter
Of course the real problem with this query is the sales data. All rows of the sales table will be fetched back to Intelligence Central, and then many will simply be discarded because they are excluded by the join to the customer data. Depending upon how many years of sales records are kept, together with the volume of sales annually, this table could potentially contain tens of millions of rows in a real production environment.
When you provide a filter in the SQL WHERE clause, Intelligence Central will push that filter down to the remote database wherever possible. This is done to minimize the copying of redundant data across the network. Reducing the size of each data transfer is the fastest way to speed up cross-database query performance.
Therefore, adding filters directly to the sales table will make a huge difference to the performance of this query. This revised edition adds a country name filter directly to the sales table:
SELECT x.customer_name, s.sales_amount, s.sales_quantity
FROM sales_db.sales s
JOIN (
SELECT c.customer_key, c.customer_name
FROM cust_db.customer c
JOIN cust_db.geography g ON g.geography_key = c.geography_key
WHERE g.country_name = 'Japan'
) x ON x.customer_key = s.customer_key
WHERE s.country_name = 'Japan'
In a normal RDBMS, adding the same WHERE clause condition to multiple tables is redundant because the relational join will naturally propagate restrictions on one table to each other table in the query.
With the cross-database query however, we want to push as many filters as possible to each contributing database to minimise the amount of data copied over the network. Adding the redundant country name filter will cause Intelligence Central to also push the “Japan” restriction down to the sales database when it executes the sales_db sub-query. This could easily prevent millions or even tens of millions of sales rows from being needlessly copied to Intelligence Central, only to be discarded in the subsequent join to the cust_db data.
This kind of simple yet profound performance gain reinforces the need to understand how Intelligence Central will deconstruct the cross-database query to fetch data from each contributing database.
A good rule of thumb is to apply every filter you possibly can to each table in the query.
Put Small Tables First
For instance, this query joins two tables:
SELECT c.customerLabel, s.salesAmount, s.salesQuantity
FROM sales_db.sales s
JOIN cust_db.customer c ON c.customer_key = s.customer_key
A second version of the same query reverses the order of the tables:
SELECT c.customerLabel, s.salesAmount, s.salesQuantity
FROM cust_db.customer c
JOIN sales_db.sales s ON s.customer_key = c.customer_key
If the sales table fits into memory when sorted, then performance of both these queries is comparable. However, the customer table can always be sorted in memory. So if the sales table is too large to sort in memory then the first version of the query will go from minutes to hours; whereas the second version of the query will scale appropriately with performance that is linear compared with the number of sales rows.
Publishing Queries
The performance overhead of publishing a view arises from incurring an additional step of copying the query results from Intelligence Central to the Toad client. Instead of executing the view’s query within the Toad client, a published view is executed in a remote instance of the Toad Intelligence Central server, and the results are forwarded to the Toad client.
The extra overhead is proportionate to the size of the result set that must be forwarded from Intelligence Central to the client. Consider a view whose query looked like this:
SELECT c.customerLabel, s.salesAmount, s.salesQuantity
FROM sales_db.sales s
JOIN cust_db.customer c ON c.customer_key = s.customer_key
This query would involve fetching sales and customer data to Intelligence Central, and forwarding all of that data on a subsequent network trip to the Toad client. Publishing a view that returns largely unprocessed data like this may almost double the amount of time required to query the view from a Toad client.
Alternately, a view could be implemented to summarize sales data:
SELECT c.customerLabel, SUM(s.salesAmount), SUM(s.salesQuantity)
FROM sales_db.sales s
JOIN cust_db.customer c ON c.customer_key = s.customer_key
GROUP BY c.customerLabel
Querying this version of the view would still entail fetching all sales and customer data to Intelligence Central, but then the summarized result set would be relatively small. It would take very little time for Intelligence Central to forward this result set to the Toad client. Therefore, publishing a view such as this should incur very little additional overhead.
Start the discussion at forums.toadworld.com